
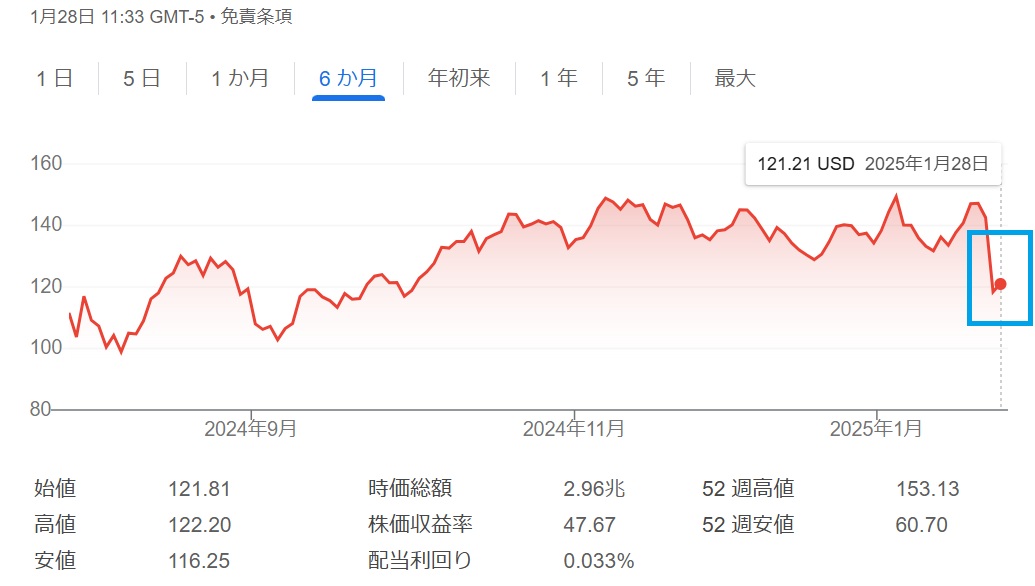
「DeepSeekショック」という言葉を耳にし、いったい何が起こったのかと疑問を抱く方は多いかもしれません。AIに使われるGPUなどを作っているNvidiaなどの株価が2025年1月に暴落しました。
実は、この騒動には“低コストで超高性能を発揮できるMoE(Mixture of Experts)”や“OpenAIの謎のリーズニング手法を再現する技術”など、驚きの事実が隠れています。
本記事では、その技術的背景や経済的インパクトをわかりやすく整理し、「なぜこれほど注目されているのか」「私たちの生活やビジネスにどう影響するのか」といった疑問を解消します。読めば、最新AIの“今”と“これから”をつかむヒントを得られるはずです。
DeepSeekショックとは何か

最近、マーク・アンドリーセン氏が「スプートニクショック」とまで称し、大きな衝撃をもたらした現象が「DeepSeekショック」です。
投資界やメディアで話題が絶えないのは、NVIDIA株価が一時90兆円分も吹き飛ぶほどの経済的インパクトや、ナスダック総合指数が3%も下落するといった、世界市場への影響が甚大だったからです。
では、なぜDeepSeekショックがこれほどまでに注目を集めたのでしょうか。その理由としては、大きく以下の三つが挙げられます。
DeepSeekショックが注目を集めた理由
- MoE(Mixture of Experts)技術を使って、フロンティアモデル並みの性能を圧倒的に低コストで実現したこと
- OpenAIのo1モデルが示唆していた“リーズニング”の仕組みをほぼ同等に再現し、性能を飛躍的に高めたこと
- それを成し遂げたのが、中国の“今まで注目度が低かった企業”であるDeepSeekだったこと
以下では、これら三つのポイントを中心に、より詳しく解説していきます。
1. MoE技術の詳細と背景

1-1. DeepSeek-V3の驚異的な学習コスト削減
DeepSeekが開発したモデル「V3」はパラメータ数が6700億(670B)もあり、学習トークン数は14.7テラトークンに及びます。通常、これほど巨大なモデルを学習するには莫大な計算資源と時間が必要です。
たとえば、Llama3がパラメータ数400B規模で15テラトークンほどを学習した際は、H100を1万6000台も使い、3か月ほどを要しました。しかし、DeepSeekはアメリカの輸出規制によって性能が下げられたH800を2000台、2か月で学習を完了し、コストを約1/20にまで削減。総額でも10億円はかからない見込みとされています。
1-2. MoEの仕組みと課題
MoE(Mixture of Experts)自体は決して新しい技術ではありません。Googleが2017年頃に大規模ネットワークに導入し、OpenAIのGPT-4にも採用されていると推測されています。
その中身を簡単に言うと、モデルを多数のエキスパートに分割し、各トークンごとに一部のエキスパートのみを動かす設計です。必要な計算量は減らせる反面、メモリやネットワーク転送がボトルネックになりやすい問題があります。
一般的に計算性能は年々飛躍的に向上していく一方、メモリ帯域やネットワーク性能は追いつきにくいという課題があります。ゆえに「MoEは効率が悪い」と思われがちでしたが、DeepSeekはそこにあえて“逆張り”し、大規模実装を成功させたわけです。
1-3. 今後のMoE普及の可能性
では、これを機に誰もがMoEを採用するかというと、そうとも言い切れません。大規模モデルをさらに巨大化するよりも、学習データの質を上げる方法や、後述する強化学習などに注目が集まっています。
ただし、学習コストや推論コストを下げるという観点では、MoEが活きる可能性は十分にあります。専門分野ごとにエキスパートを細分化し、さらなるスパース化を進めれば、理論上は学習や推論の計算を1/10にするといった未来もあり得るでしょう。
2. DeepSeek-R1と“思考する”AI

2-1. リーズニング強化学習の解明
二つ目の注目ポイントは、リーズニング(思考過程)の成功事例です。OpenAIのo1モデルが高いタスク達成能力を示していたものの、具体的な仕組みは謎でした。そこへDeepSeekが投入したのが、強化学習を用いた「R1」。
数学やコードの問題のように、正解を客観的に評価できるタスクで、回答を複数生成しては報酬を与えるというシンプルな強化学習を行い、わずか1万ステップでo1並みの性能に到達しています。
2-2. R1-ZeroからR1への進化
最初の実装段階では、思考過程が英語や中国語など多言語で混在してしまうなど、人間が解読しにくい問題がありました。そこでSFT(教師ありファインチューニング)を取り入れ、“人間が読み取れるレベル”に仕上げたものがR1です。
R1は依然として大規模かつMoE構造のため扱いづらい面もありますが、一度獲得した高い能力を、小さなモデルに蒸留できるのも大きな特徴です。結果として、「Qwen」や「Llama」といった既存の標準的なモデルでも最高水準の性能を叩き出す報告がされています。

2-3. 強化学習の今後の展望
強化学習で高い能力を獲得するには、ある程度賢いベースモデルが必要とされています。逆に、ベースモデルが十分優秀ならば、強化学習によって学習データにもない“新たな思考過程”を身につけられるわけです。
さらに、一度大モデルで獲得した能力は、後から小さいモデルに移せます。今後はまず大規模モデルをしっかり育て、それを強化学習で飛躍させてから、小規模モデルへ蒸留という流れが主流になるかもしれません。
DeepSeekショック:まとめと展望

「DeepSeekショック」がここまで世間の注目を浴びるのは、コスト効率を大幅に改善するMoEの成功例であることと、LLMに“思考能力”を実装し得る強化学習を示した点が大きいと言えます。
深まるAIの可能性をどう活かし、どこにリスクを感じるのか——これからのビジネス戦略や社会の在り方を考える上で、「DeepSeekショック」の事例は大きなヒントを与えてくれます。最新技術の先にある未来を、私たちの目でしっかりと見極めたいものです。

