

Sanaka AIが開発した「TinySwallow-1.5B」は、最新の知識蒸留手法「TAID(Temporally Adaptive Interpolated Distillation)」を用いて構築された、小規模ながら高性能な日本語言語モデルです。このモデルは約15億のパラメータを持ち、同規模のモデルの中で最高水準の日本語ベンチマークスコアを達成しています。
TinySwallow-1.5Bは、PCやスマートフォンなどのローカル環境での動作を前提に設計されており、オフラインでの利用が可能です。NvidiaのGPUを搭載していないノートPCでも、ローカル環境でTinySwallow-1.5Bを動かくことができます。
TinySwallow-1.5BをLM Studioで動かす手順
LM Studioは、ローカル環境で大規模言語モデル(LLM)を探索、ダウンロード、実行できるツールです。これにより、インターネット接続がない環境でも、LLMを活用した自然言語処理が可能となります。
Sanaka AIのTinySwallow-1.5Bモデルをローカル環境で動作させるための手順をご案内いたします。以下の手順に従ってください。
LM Studioのインストール:
LM Studioは、ローカルで大規模言語モデルを実行するためのツールです。公式サイトから最新バージョンをダウンロードし、インストールしてください。
Hugging FaceでTinySwallow-1.5Bモデルを選択:
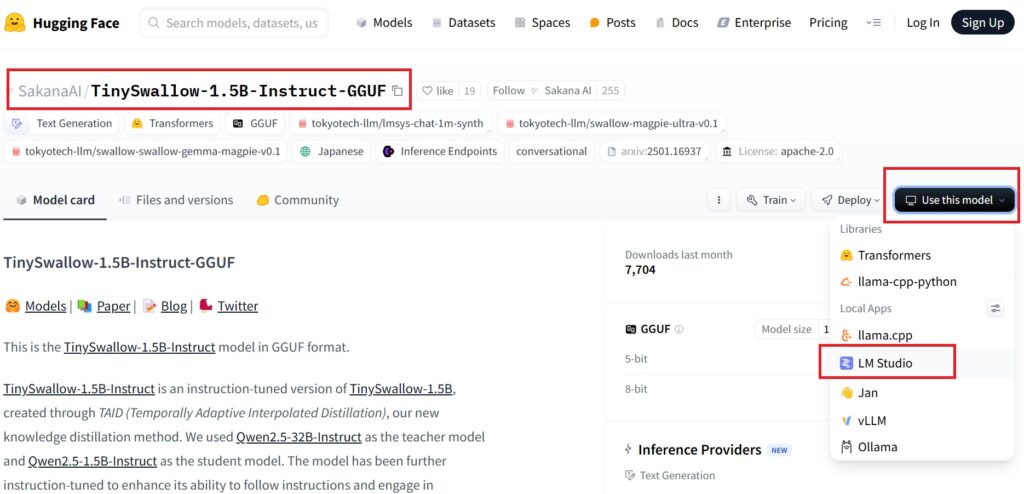
Sanaka AIのTinySwallow-1.5Bモデルを入手するためには、以下の手順を行います。
Hugging FaceのSanaka AI公式ページにアクセスします。
「SakanaAI/TinySwallow-1.5B-Instruct-GGUF」というモデルを選択してください。
Hugging Face公式ページのリンク: Sanaka AI TinySwallow-1.5B
LM Studioでダウンロードを実行
LM Studioが起動してから、TinySwallow-1.5Bモデルをダウンロードします。
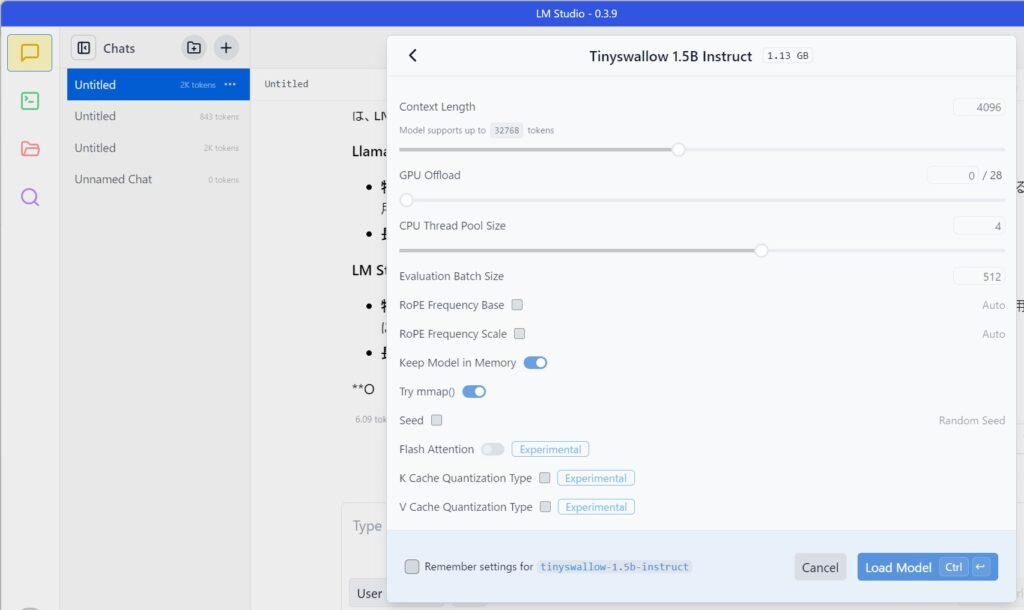
LM Studioでモデルをロード:
LM Studioを起動し、インターフェースから先ほど配置したTinySwallow-1.5Bモデルをロードします。
モデルのロードが完了したら、動作確認として簡単なプロンプトを入力し、モデルが正常に応答するか確認してください。
NvidiaのGPUがないPCでも、十分に早いスピードで文章を生成します。
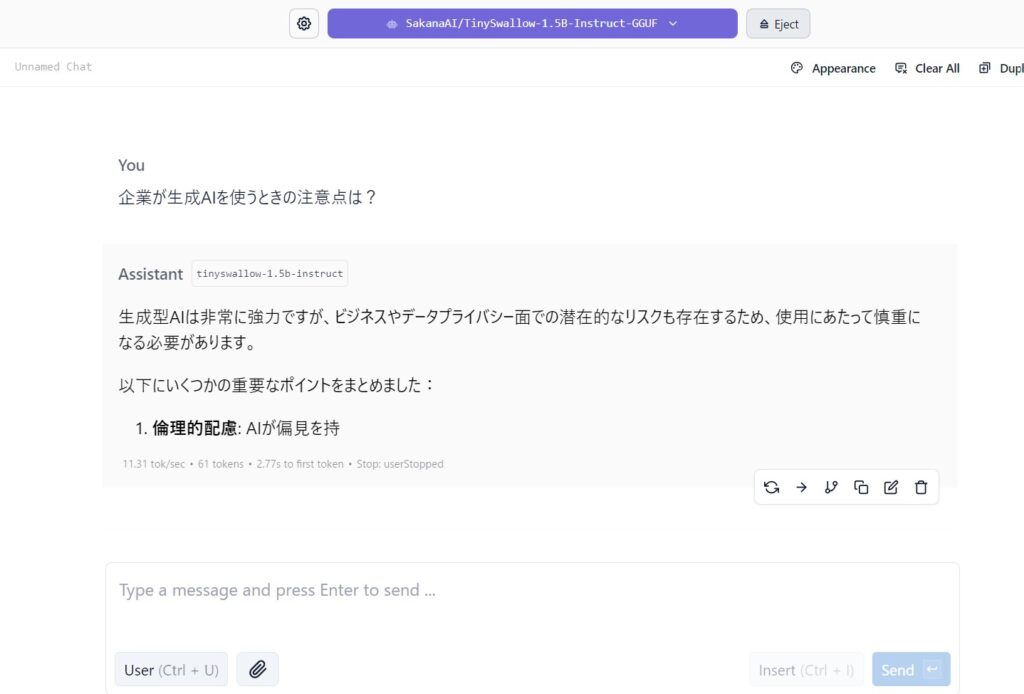
動作確認と最適化:
モデルが正常に動作することを確認したら、必要に応じてLM Studioの設定を調整し、パフォーマンスの最適化を行ってください。
LM Studioで業務データを活用するには?
LM StudioのRAG機能
LM Studioでは、RAG(Retrieval Augmented Generation)を活用して、ユーザーがアップロードしたドキュメントから情報を取得し、それをもとにLLM(大規模言語モデル)が回答を生成できます。これは、事前に学習されたデータだけでなく、ユーザーが提供する特定の文書に基づいて、より的確な回答を得るための技術です。
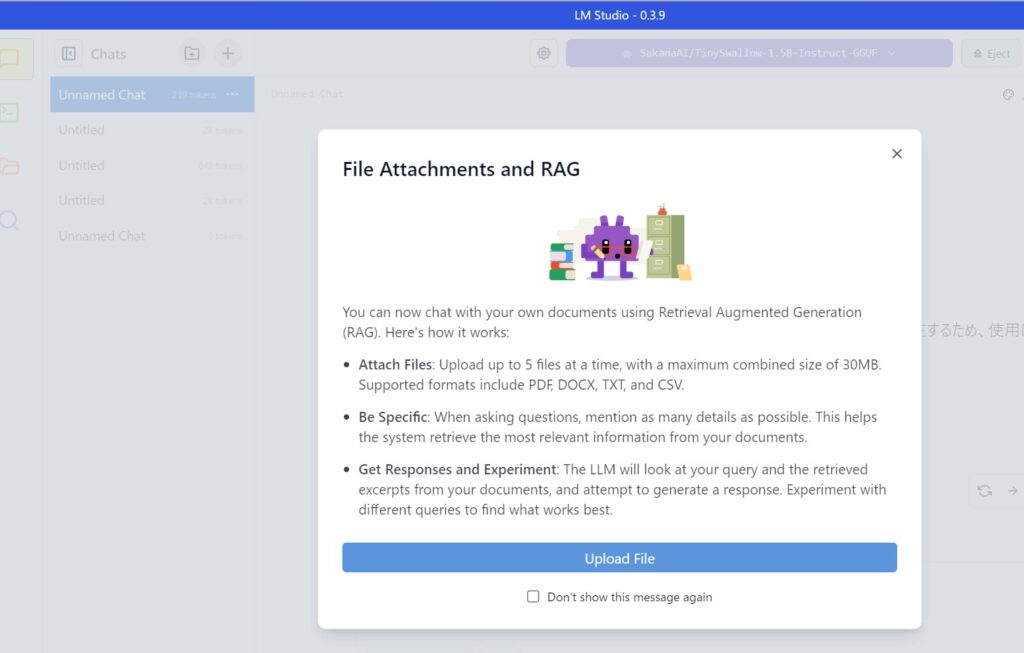
主な機能
- ファイルのアップロード
- ユーザーは最大 5つのファイル を同時にアップロード可能。
- 合計 30MB までのファイルを扱える。
- 対応フォーマット: PDF, DOCX, TXT, CSV。
- 詳細な質問を推奨
- ユーザーの質問が具体的であればあるほど、関連する情報を正確に取得しやすくなる。
- 例:「2023年の売上データについて教えてください」よりも、「2023年のQ3の売上データをCSVから取得し、前年比と比較してください」のほうが精度が向上。
- 検索と回答の生成
- アップロードしたファイル内の情報を検索し、該当する部分を抽出。
- LLMがその情報をもとに回答を生成。
- ユーザーは異なる質問を試すことで、より適切な回答を得られる。
活用例
- レポート分析: PDFのレポートをアップロードし、要点を自動で要約。
- 契約書チェック: DOCXの契約書から特定の条項を検索し、解説を得る。
- データ分析: CSVファイルの売上データから傾向を抽出し、グラフの作成をサポート。
LM StudioのRAG機能を使えば、ユーザー自身のデータを活用しながら、より的確な情報を得ることが可能になります。
