

昨今、大規模言語モデル(LLM)の活用が企業の競争力を左右する時代となっています。しかし、クラウドベースのAIサービスではデータプライバシーやコスト面での課題が残っていることでしょう。
本記事では、こうした課題を解決する方法として、日本語対応のオープンソースLLMをローカル環境で活用し、自社のニーズに合わせたカスタマイズを行う方法を解説します。具体的には、モデルのファインチューニング手法と、外部知識を活用するRAG(Retrieval-Augmented Generation)の構築手順を、実践的なステップに沿って説明していきます。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
ローカルLLMとは何か

ローカルLLMとは、自社のPC、サーバー、オンプレミス環境、プライベートクラウドなどで動かす大規模言語モデルのことです。
ChatGPTやClaude、Geminiのようなクラウド型AIは、インターネット経由でAIサービスにアクセスして利用します。一方、ローカルLLMは、自社管理下の環境でモデルを動かせる点が大きな特徴です。
ローカルLLMを使うことで、入力した情報を外部のAIサービスに送らずに処理できます。そのため、機密情報、顧客情報、社内文書、研究データ、契約書、技術資料などを扱う企業にとって、安全性を高めやすい選択肢になります。
ただし、ローカルLLMは、単にモデルをインストールすれば終わりではありません。業務で使うには、GPU環境、モデル選定、RAG基盤、権限管理、ログ管理、セキュリティ設計、運用保守まで含めた設計が必要です。そのため、現在のローカルLLM導入は、完全ローカルにこだわるというより、クラウドAI、ローカルLLM、RAGを用途に応じて使い分けるハイブリッドAI構成が現実的になっています。
なぜローカルLLMが注目されているのか
ローカルLLMが注目されている理由は、大きく3つあります。
1つ目は、セキュリティです。クラウドAIでは、入力した情報が外部サービスに送信されます。法人向けプランではデータ保護機能が強化されていますが、それでも業種や社内規程によっては、外部送信そのものが難しいケースがあります。
2つ目は、社内データ活用です。企業には、マニュアル、議事録、営業資料、FAQ、問い合わせ履歴、仕様書、契約書など、多くのナレッジが蓄積されています。しかし、これらの情報は部署ごとに分散し、必要な時に探しにくいことも少なくありません。ローカルLLMとRAGを組み合わせれば、社内データを検索しながら回答するAIを構築できます。
3つ目は、コストと運用の柔軟性です。クラウドAIは便利ですが、利用量が増えるほどAPI料金やサブスクリプション費用が膨らむ場合があります。ローカルLLMは、一定以上の利用量がある場合、API従量課金を抑えられる可能性があります。
ただし、ローカルLLMが必ず安いわけではありません。GPUサーバー、電力、保守、監視、モデル更新、RAG基盤、エンジニア人材などの費用が発生します。コスト削減だけを目的にするのではなく、セキュリティ要件、利用量、業務効果、運用体制を含めて費用対効果を判断することが大切です。
ファインチューニングとは
ファインチューニングとは、既存のLLMに追加学習を行い、特定の業務や目的に合うように調整する手法です。たとえば、以下のような目的で使われます。
| 目的 | 内容 |
|---|---|
| 文章スタイルの統一 | 企業らしい文体や回答ルールに近づける |
| 分類タスクの精度向上 | 問い合わせ分類、レビュー分類、リスク判定などに使う |
| 定型業務への適応 | 決まった形式の回答やレポート作成に強くする |
| 業界用語への適応 | 特定分野の言い回しや表現に慣れさせる |
| 応答形式の固定 | JSON、表、定型フォーマットで出力しやすくする |
以前は、社内情報をAIに覚えさせるためにファインチューニングするという説明も多くありました。しかし現在は、頻繁に更新される社内文書や規程を覚えさせる用途では、ファインチューニングよりRAGの方が実務的です。
ファインチューニングは、新しい知識を大量に覚えさせるより、回答の振る舞い、文体、分類、フォーマット、業務特化のパターンを調整する手段と考えるとわかりやすいでしょう。
RAGとは
RAGとは、Retrieval Augmented Generationの略で、検索拡張生成と呼ばれる手法です。LLM単体では、学習時点以降の情報や社内独自の情報を知りません。そこで、回答を生成する前に社内文書やデータベースから関連情報を検索し、その内容をもとに回答させるのがRAGです。
たとえば、社内マニュアルをRAGに登録しておけば、社員が質問した時に、AIが関連する文書を検索し、その内容に基づいて回答できます。RAGの基本的な流れは以下の通りです。
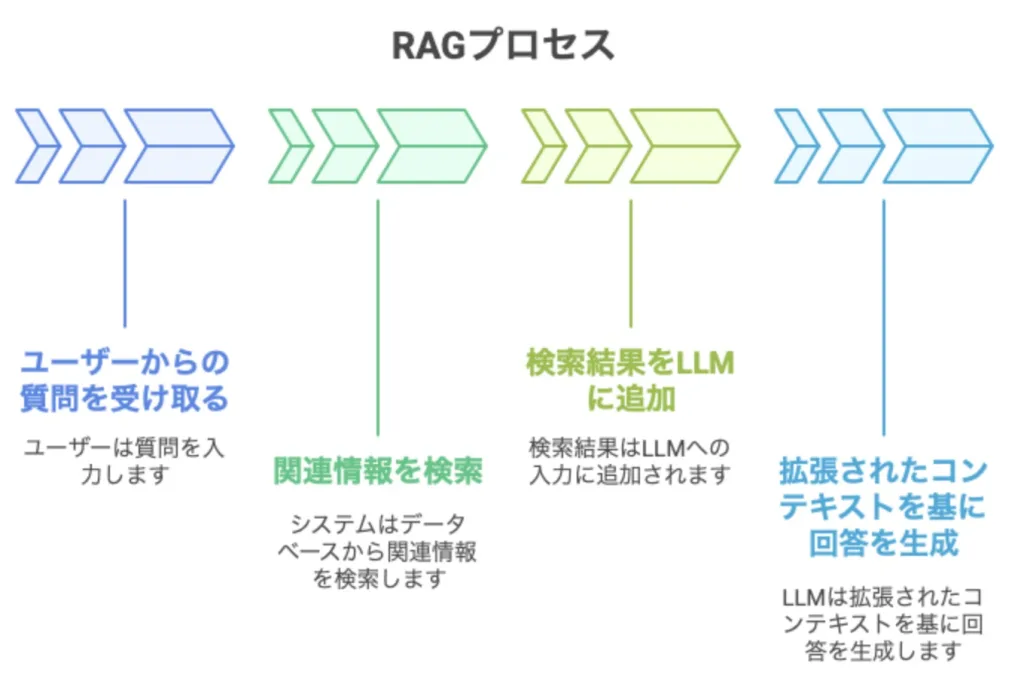
RAGの利点は、モデル自体を再学習しなくても、社内情報を活用できることです。マニュアルや規程が更新された場合も、データベース側を更新すればよいため、運用しやすいというメリットがあります。
ファインチューニングとRAGの違い

ファインチューニングとRAGは、どちらもLLMを業務に適応させる手法ですが、役割は異なります。
| 項目 | ファインチューニング | RAG |
| 主な目的 | モデルの振る舞いや文体を調整する | 外部情報を検索して回答に反映する |
| 向いている情報 | 比較的変わりにくいルールや出力形式 | 頻繁に更新される社内文書やナレッジ |
| 更新方法 | 再学習や追加学習が必要 | 文書データベースを更新する |
| 得意な用途 | 分類、定型出力、文体統一 | 社内FAQ、規程検索、資料検索 |
| 注意点 | 学習データの品質が重要 | 検索精度と権限管理が重要 |
実務では、まずRAGを導入し、それでも足りない部分を軽量ファインチューニングで補う流れが現実的です。
ローカルLLMで使われる代表的なモデル

ローカルLLMの選択肢は、ここ数年で大きく広がりました。以前はLlamaやGemmaなどが代表的でしたが、現在はより高性能なオープンウェイトモデルが増えています。代表的な候補は以下の通りです。
| モデル系統 | 特徴 |
| Llama 4 | Metaのオープンウェイトモデル。マルチモーダルや長文コンテキストに対応 |
| Gemma 4 | Googleのオープンモデル。推論やエージェント用途を意識した設計 |
| gpt-oss | OpenAI系のオープンウェイトモデル。20Bと120Bがあり、ローカル推論やエージェント用途に対応 |
| Qwen系 | 多言語、コーディング、業務用途で候補になりやすい |
| Mistral系 | 軽量、高速、欧州系モデルとして法人利用の候補 |
| DeepSeek系 | 推論やコストパフォーマンスを重視する場合の候補 |
ローカルLLMを選ぶ際に注目したい箇所は?
モデルを選ぶ際は、単純な性能だけで判断しないことが重要です。見るべきポイントは、以下のようになります。
| 選定項目 | 確認ポイント |
| 日本語性能 | 日本語の業務文書に対応できるか |
| 必要なGPU | 自社環境で動かせるサイズか |
| ライセンス | 商用利用や再配布の条件に問題がないか |
| コンテキスト長 | 長い文書や会話を扱えるか |
| 推論速度 | 業務で使える応答速度か |
| RAGとの相性 | 検索結果を正しく使えるか |
| 運用実績 | コミュニティや導入事例があるか |
企業導入では、最新モデルだから良いとは限りません。小規模なモデルでも、RAGと組み合わせれば十分に実用的な場合があります。逆に、大規模モデルを選ぶと、GPUコストや運用負荷が大きくなることもあります。
ローカルLLM導入の基本ステップ

ローカルLLMを企業で導入する場合、以下の流れで進めると整理しやすくなります。
ステップ1: 環境の準備
まず、Pythonや必要なライブラリ(例: transformers, langchain, chromadbなど)をインストールします。Google Colaboratoryやローカル環境での実行が可能です。
また、Hugging Faceに登録し、モデルへのアクセス権を取得します。Llama系モデルはGated Modelとして提供されているため、利用権限の申請が必要です。
ステップ2: モデルの選定とファインチューニング
続いてモデル選定とファインチューニングを行います。
モデルの選定
日本語対応のオープンソースLLMから適切なモデルを選びます。たとえば、Meta社のLlamaやGoogle社のGemmaなどが候補です。
ファインチューニング
選定したモデルを特定のタスクに合わせてファインチューニングします。LoRA(Low-Rank Adaptation)などの手法を用いることが一般的です。

以下のPythonコードを使用してファインチューニングを実行します。このコードでは、Meta社のLlama 3(8Bパラメータ版)をベースモデルとして使用し、LoRA手法によって効率的なファインチューニングを行っています。
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# LoRA設定
lora_config = LoraConfig(r=64, lora_alpha=16, lora_dropout=0.1)
trainer = SFTTrainer(model=model, tokenizer=tokenizer, peft_config=lora_config)
trainer.train()
ステップ3:RAG構築
RAGは情報検索と生成を組み合わせた手法です。以下の手順でRAGを構築します。
データベースの準備
RAGでは外部データベースから情報を取得するために、ChromaDBなどのベクトルストアを使用します。データベースには関連する文書や情報を格納しておきます。
情報検索機能の実装
LangChainなどを用いて、ユーザーからの質問に対して関連する情報をデータベースから検索する機能を実装します。
生成モデルとの統合
検索した情報を基に生成モデルが回答を生成するように設定します。以下はその一例です。
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
# ベクトルストアから情報取得
vectorstore = Chroma.from_documents(texts, embeddings)
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 質問応答
response = qa_chain.run("データアナリティクスラボ株式会社について教えてください。")
ステップ4: テストと評価
構築したRAGシステムが正しく動作するかどうかテストします。様々な質問に対して期待通りの回答が得られるか確認し、必要に応じてモデルやデータベースの調整を行います。

RAG運用で重要な注意点
RAGは便利な仕組みですが、ただ文書を登録するだけでは十分ではありません。実務で使うには、いくつかの注意点があります。
権限管理が必要
社内文書には、全社員が見てよい情報もあれば、特定部署だけが見られる情報もあります。RAGでは、検索結果に含まれる文書をAIが参照するため、権限管理を誤ると、本来見てはいけない情報が回答に含まれる恐れがあります。部署、役職、プロジェクト、顧客ごとに参照範囲を制御する設計が必要です。
引用元表示が重要
AIの回答が正しいかどうかを確認するには、どの文書をもとに回答したのかを表示できることが重要です。引用元が表示されれば、社員は元の資料を確認できます。これにより、ハルシネーションのリスクを下げ、AIの回答を業務で使いやすくなります。
文書更新の運用が必要
社内規程やマニュアルは更新されます。古い文書がRAGに残っていると、AIが古い情報をもとに回答してしまいます。そのため、文書の追加、削除、改訂をどう反映するかを事前に決める必要があります。RAGは作ることよりも、運用し続けることが重要です。
検索精度を継続的に評価する
RAGでは、回答生成の前に正しい文書を検索できるかが品質を左右します。検索が間違っていれば、どれだけ高性能なLLMを使っても正しい回答は期待できません。業務でよくある質問をテストケースとして用意し、検索結果と回答を定期的に確認する仕組みが必要です。
ローカルLLMのメリット

ローカルLLMには、以下のようなメリットがあります。
| メリット | 内容 |
| 情報管理しやすい | 社内環境で処理できるため、外部送信を避けやすい |
| 社内データを活用できる | RAGと組み合わせて社内文書を参照できる |
| カスタマイズしやすい | モデル、RAG、UI、権限管理を自社要件に合わせられる |
| コストを制御しやすい場合がある | 大量利用ではAPI従量課金を抑えられる可能性がある |
| オフラインや閉域網で使える | インターネット接続が制限される環境でも運用しやすい |
とくに、金融、製造、医療、法務、研究開発、自治体など、情報管理が厳しい領域では、ローカルLLMが選択肢になりやすいです。
ローカルLLMの注意点
一方で、ローカルLLMには注意点もあります。
| 注意点 | 内容 |
| 初期構築が必要 | GPU、サーバー、RAG基盤などの設計が必要 |
| 運用保守が必要 | モデル更新、障害対応、ログ管理が必要 |
| 精度評価が必要 | 回答品質を継続的に確認する必要がある |
| 人材が必要 | AI、インフラ、セキュリティに詳しい人材が必要 |
| コストが見えにくい | GPU費用や保守費用が後から膨らむ場合がある |
ローカルLLMは、クラウドAIより安全で安い万能策ではありません。セキュリティを重視する代わりに、運用の責任も自社側に移ります。
そのため、導入時には小さく始めることが重要です。いきなり全社導入を目指すのではなく、社内FAQ、特定部署のマニュアル検索、技術文書検索など、範囲を絞ったPoCから始めるとよいでしょう。

業務での活用例
ローカルLLM、RAG、ファインチューニングを組み合わせることで、さまざまな業務に活用できます。
社内FAQ
社内規程、総務マニュアル、ITヘルプデスクのFAQをRAGに登録し、社員が自然文で質問できるようにします。問い合わせ対応の負担を減らし、必要な情報を探す時間を短縮できます。
技術文書検索
製造業やIT企業では、仕様書、設計書、障害対応履歴、過去のナレッジを検索できるAIとして活用できます。属人化していた知識を共有しやすくなります。
営業資料作成
製品資料、事例、提案書、FAQをもとに、営業向けの提案文や説明資料を作成できます。RAGで正しい情報を参照し、ファインチューニングで自社らしい表現に近づけることも可能です。
カスタマーサポート支援
問い合わせ履歴やサポートマニュアルを参照し、回答案を作成できます。ただし、顧客への最終回答は人が確認する運用が必要です。
医療や金融、法務の支援
医療、金融、法務などの高リスク領域では、AIに最終判断を任せるのではなく、文書整理、規程検索、記録要約、レポート作成の補助として使うのが現実的です。
たとえば、医療文書の要約、院内マニュアル検索、金融規程の確認、契約書レビューの補助などが考えられます。最終判断は必ず専門家や担当者が行う必要があります。
法人向けのローカルLLMサービス
LM StudioやOllamaなどを使えば、個人のPCでローカルLLMを動かすことは可能です。ただし、自社データを活用したローカルLLMを構築したい場合は、RAGの機能が不足しています。
法人向けにおすすめのローカルLLMサービスにご興味がある方は以下をご覧ください。

クラウドAIとローカルLLMはどう使い分けるべきか
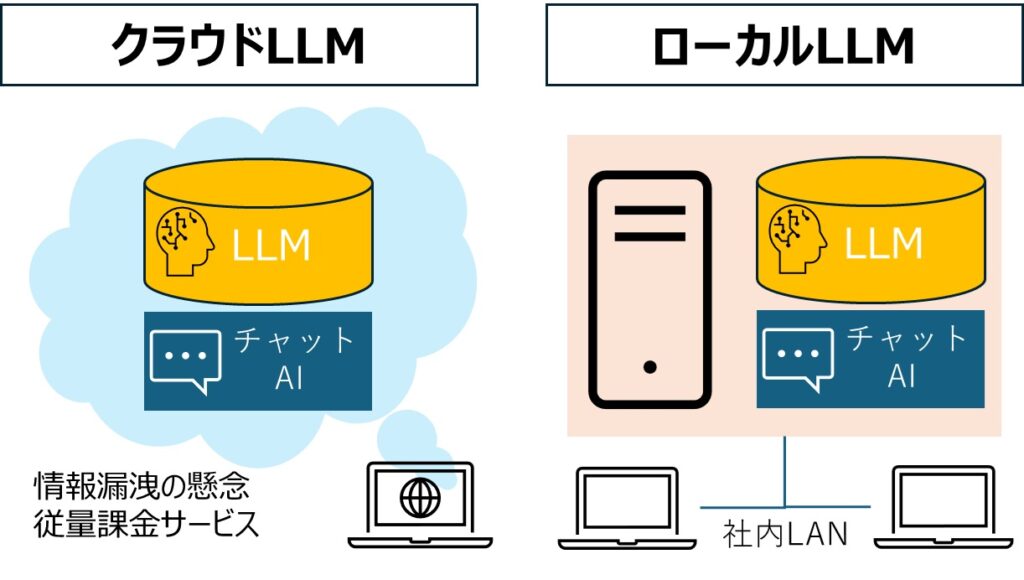
これからの企業AI活用では、クラウドAIとローカルLLMのどちらか一方を選ぶのではなく、用途に応じて使い分けることが重要です。
| 用途 | 向いている選択肢 |
| 一般的な文章作成 | クラウドAI |
| 最新情報の調査 | Web検索対応のクラウドAI |
| 機密情報を含む社内文書検索 | ローカルLLM+RAG |
| 高度な推論や分析 | 高性能クラウドAI |
| 閉域網での利用 | ローカルLLM |
| 大量の定型問い合わせ | ローカルLLMまたはハイブリッド構成 |
| 社内ナレッジ活用 | RAG中心の構成 |
クラウドAIは性能や使いやすさに優れています。一方、ローカルLLMは情報管理やカスタマイズ性に強みがあります。現実的には、社外秘ではない一般業務にはクラウドAI、機密性の高い社内情報にはローカルLLMやRAGを使うというハイブリッド構成が有力です。
導入前に確認すべきチェックリスト
ローカルLLMを導入する前に、以下の項目を確認しておきましょう。
| 確認項目 | チェック内容 |
| 利用目的 | 何の業務を効率化したいのか |
| 対象データ | どの社内文書を使うのか |
| 機密性 | 外部送信できない情報か |
| 権限管理 | 誰がどの情報を参照できるのか |
| モデル選定 | 日本語性能、ライセンス、GPU要件は適切か |
| RAG設計 | 引用元表示や文書更新に対応できるか |
| 評価方法 | 正確性や検索精度をどう検証するか |
| 運用体制 | 誰が保守、監視、改善を行うのか |
| コスト | GPU、保守、人材、運用費を含めて見合うか |
このチェックを行うことで、技術ありきではなく、業務目的に合った導入がしやすくなります。
ローカルLLM:まとめ

今後、企業の生成AI活用は、クラウドAIだけでなく、ローカルLLM、RAG、ファインチューニングを組み合わせたハイブリッド構成へ進んでいくでしょう。情報管理と業務効率化を両立したい企業にとって、ローカルLLMは検討すべき重要な選択肢です。


