

この記事では、OpenAIが開発した最新のAIモデルが、国際情報オリンピック(IOI)やプログラミングコンテストサイトCodeforcesで、なんと人間のトップレベルに匹敵する成績を収めたという驚きの事実を紹介します。
国際情報オリンピックで金メダル獲得!その詳細な戦略とは?
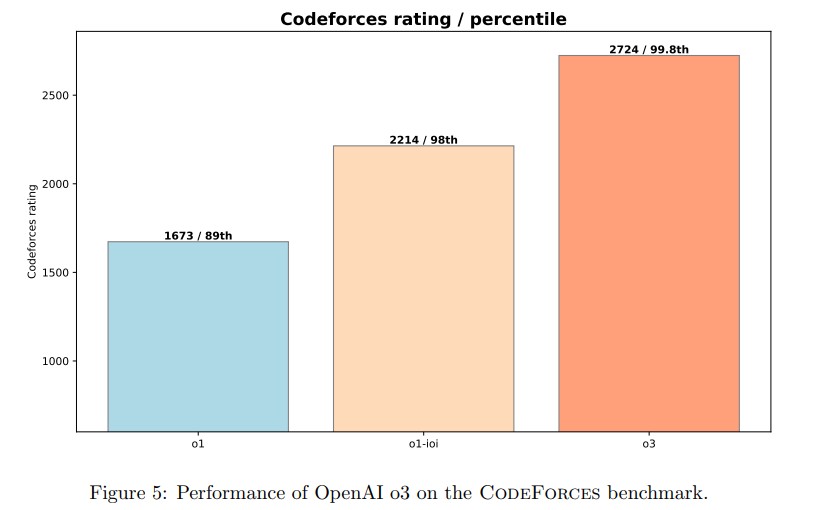
2024年に開催された国際情報オリンピック(IOI)で、OpenAIは3つのシステムで挑戦しました。「o1」、「o1-ioi」、そして最新の「o3」です。
o1
o1はOpenAIの最初の推論モデルで、一般的な手法を用いてプログラミングのパフォーマンスを向上させました。
o1-ioi
o1をベースに、IOI 2024に特化して微調整されたシステムです。人間の競技プログラマーと同様の条件下で参加し、49パーセンタイルの成績(上位49%)を収めました。これは、人間が手作業で最適化した戦略を用いた結果です。一方、以下のように競技の制約を緩和した環境では金メダルを獲得する結果となりました。金メダルボーダーは359.71点(30位)です。
o1-ioiの戦略
- 問題分割: 各IOIの問題を個別のサブタスクに分割。
- 候補生成: 各サブタスクに対して、10,000個もの解答候補を生成。
- クラスタリング: モデルが生成したテスト入力に対する出力に基づいて、解答候補をクラスタリング。
- 再ランキング: 学習済みのスコアリング関数、モデル生成テストでのエラー、公開テストケースの失敗などを考慮して、各クラスタにスコアを付与。
- 提出: 最も難しいサブタスクから順に、最大50個の解答を提出。
o3
さらに注目すべきは、o1-ioiよりも新しいモデルである「o3」です。
o3は、特別な戦略なしに、IOI 2024で金メダルを獲得し、Codeforcesのレーティングでは上位0.2%に相当する成績を収めました。これは、AIが自律的に高度な問題解決能力を獲得できることを示しています。

強化学習とChain-of-Thought:AIの思考プロセスを解き明かす
これらのAIモデルの強さの秘密は、強化学習と思考の連鎖(Chain-of-Thought、CoT)と呼ばれる技術にあります。
- 強化学習:AIが試行錯誤を繰り返しながら、報酬を最大化するような行動を学習する手法です。これにより、AIは、人間が明示的にプログラミングしなくても、最適な戦略を自ら発見することができます。
- 思考の連鎖(Chain-of-Thought): AIが問題を解く過程を、人間のように段階的に思考し、言語化する能力を指します。これにより、AIは、単に答えを出すだけでなく、なぜその答えが正しいのかを説明することができます。
o1-ioiが行った強化学習
o1-ioiは、強化学習によってプログラミングタスクに特化して訓練され、さらに人間が設計した戦略によってパフォーマンスを向上させました。具体的には、C++コードの生成と実行、ランタイムチェックの改善に重点が置かれました。
o3の驚くべき自律性
一方、o3は、強化学習によって自律的に高度な推論能力を獲得し、人間が介⼊しなくても⾦メダルを獲得できるレベルに到達しました。o3は、o1-ioiのようにサブタスクごとに解答を生成するのではなく、以下の流れで問題全体に対して一度に解答を生成します。
- 自己テスト: 問題を解くために、まず自分でテストケースを作成します。
- コード検証: 生成したコードをテストし、その結果に基づいてコードを修正します。
- 戦略的思考: 検証が難しい問題に対しては、ブルートフォース(総当たり)アルゴリズムを生成し、それをより効率的なアルゴリズムと比較することで、自分の解答の正しさを検証します。

プログラミングだけじゃない!ソフトウェアエンジニアリングタスクでの実力
OpenAIのAIモデルは、プログラミングコンテストだけでなく、より実践的なソフトウェアエンジニアリングのタスクにおいても高い能力を示しています。
HackerRank Astra
実際のソフトウェア開発タスクを模倣した65個のプロジェクト指向のコーディング課題で構成されています。o1は、GPT-4oと比較して、pass@1(最初の試行で成功する確率)で9.98%、平均スコアで6.03ポイントの改善を示しました。さらに、o1-previewと比較して、pass@1で3.03%の改善を達成しました。
SWE-Bench Verified:
OpenAIの準備チームが検証したSWE-Benchのサブセットで、より信頼性の高い評価を提供します。o1-previewはGPT-4oと比較して8.1%の改善、o1はさらに8.6%の改善を示しました。o3は、o1よりもさらに22.8%も高いパフォーマンスを達成しました。
これらの結果は、AIの推論能力が、特定の分野だけでなく、より広範な実世界の課題にも応用できることを示しています。
まとめ:AIの未来、人間との協調、そして新たな課題

今回のOpenAIの成果は、AIが人間の知性を超える可能性を秘めていることを示唆しています。しかし、それは同時に、私たち人間がAIとどのように共存していくべきか、という新たな問いを投げかけているとも言えるでしょう。
参考)Competitive Programming with Large Reasoning Models

