
本記事では、最新のマルチモーダル言語モデル「Phi-4-multimodal」について詳しく紹介します。
テキスト、画像、音声を一つのアーキテクチャで取り扱う革新性、エッジデバイスでの実行にも対応できる特長など、開発者だけでなくビジネスでの活用を模索する方にも有益な情報が満載です。
Phi-4-multimodalの特徴
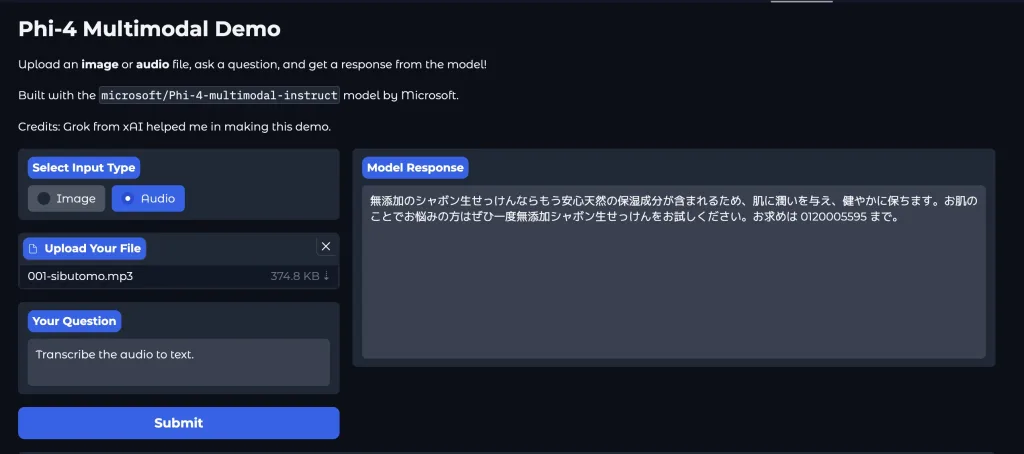
「Phi-4-multimodal」は、Microsoftが2025年2月26日に発表した初のマルチモーダル言語モデルで、テキスト・画像・音声を単一のアーキテクチャで統合的に処理できる点が大きな特徴です。
パラメータ数は5.6Bと比較的小型でありながらも、128Kトークンのコンテキスト長をサポートし、多言語対応や高い推論性能を実現しています。既存の大規模モデルに匹敵、あるいはそれ以上のパフォーマンスを示すこともあると報告されています。
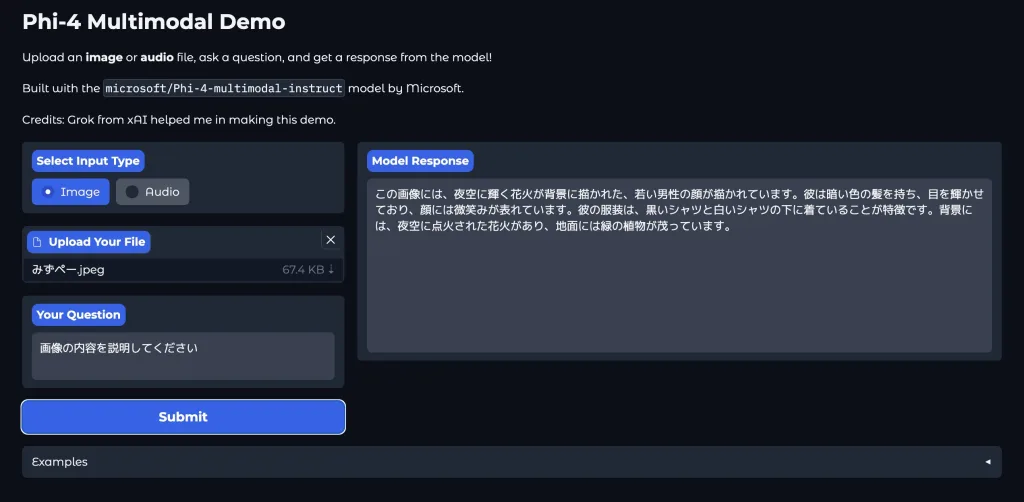
Phi-4-multimodalの開発の背景と技術的特徴
Phi-4-multimodalは、MicrosoftのPhiファミリーの新メンバーであり、「マルチモーダル」を強みに持つ小型言語モデル(SLM)です。
テキスト、画像、音声という複数のモーダルを扱うため、「Mixture of LoRAs」という技術が採用されている点が注目ポイントでしょう。モーダル間の干渉を最小限に抑えつつ、単一モデルでそれぞれの処理を行うことを可能にします。
監督付きファインチューニングと人間のフィードバックに基づく強化学習(RLHF)を導入することで、指示の正確な遵守と安全性を両立しています。音声認識の分野では、Hugging FaceのOpenASRリーダーボードでトップの性能を示し、専用モデルを上回る成果を収めているのも大きな話題となっています。
エッジデバイスへの展開とメリット
一般的に、生成AIの推論にはクラウドリソースを用いるケースが多いですが、Phi-4-multimodalはエッジデバイスでの実行を重視して設計されています。
その結果、低遅延の推論が可能になるだけでなく、クラウド利用コストの削減やデータプライバシー向上にも良い影響を与えています。IoTやモバイルなど、リソースが限られた環境下でも性能を発揮するため、幅広い業界での導入が期待されています。
Phi-4-multimodalが扱う多様なアプリケーション領域

Phi-4-multimodalが扱えるモーダルはテキスト、画像、音声です。この3つを同時に処理できることで、以下のような場面での活躍が期待できます。
- 視覚的な質問応答(VQA): 画像から得られる情報を文章化し、さらに音声化まで行うなど、人間とのやりとりをより自然に演出
- 音声認識と翻訳: 多言語対応の強みを活かしたグローバルなビジネスコミュニケーション
- ドキュメント理解: テキストや図表、画像を総合的に解析し、文脈を理解したうえでの要約や分類
また、Hugging FaceやAzure AI Foundry、NVIDIA API Catalogといったプラットフォームでモデルが提供されており、開発者はすぐに試すことが可能です。GitHubやOllamaからもアクセスできるため、コミュニティ主導の研究やプロジェクトへの応用が一段と進むでしょう。
Phi-4-multimodal:まとめ

Phi-4-multimodalは、5.6Bパラメータという小さめのモデルでありながら、テキスト、画像、音声の3種類の入力を統合的に扱う革新的なマルチモーダル言語モデルです。エッジデバイスへの展開に適した設計や強力な音声認識性能、多言語対応など、幅広い応用可能性を秘めています。
Microsoftが推進する「小型モデルのエッジ活用」という流れは今後ますます加速し、企業や開発者にとっても大きなチャンスとなるでしょう。本記事を通じて得た知見を活かし、新たなAI活用のアイデアをぜひ検討してみてください。
参考)Empowering innovation: The next generation of the Phi family

