

OpenAIが発表した最新の大規模言語モデル(LLM)「o3」が、AI研究コミュニティに大きな衝撃を与えています。この記事ではOpenAIのo3モデルが示す新たな推論アプローチについて、詳しく紹介します。
「o3」が超難関ベンチマークARC-AGIで画期的成果

o3は、「Abstract Reasoning Corpus(ARC)」をベースとした難関ベンチマーク「ARC-AGI」において、標準的な計算条件でも75.7%という驚異的なスコアを叩き出し、高い演算リソースを投じた設定では87.5%にも達しました。
これは現行のLLMが苦手としてきた「未体験タスクへの柔軟な適応」において、飛躍的な進歩を示すものとして注目を集めています。
ARC-AGIとは何か
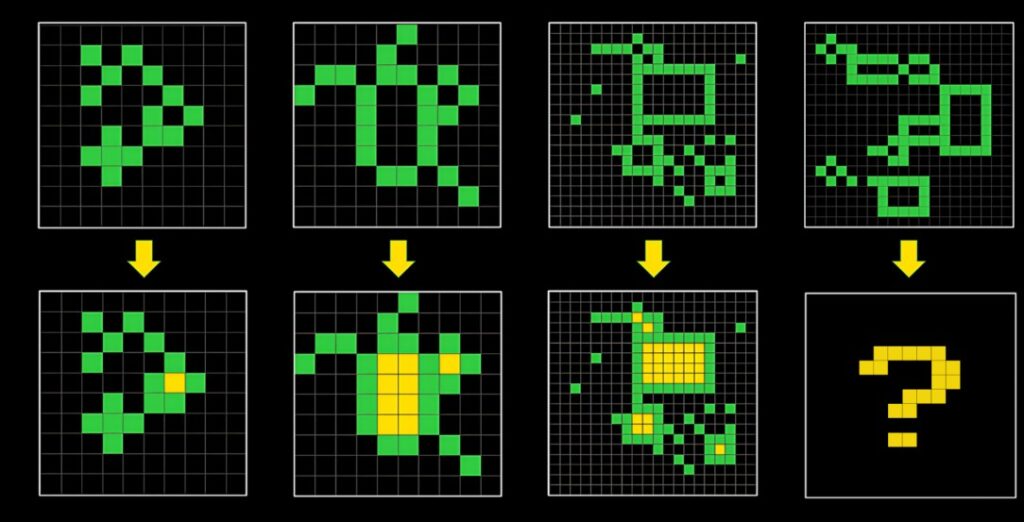
ARC-AGIは、「人間がほとんどデモなしで容易に解ける一方で、AIには極めて困難」とされる視覚パズル集「Abstract Reasoning Corpus(ARC)」をもとに、AIの汎化能力(人間でいう“流動的知能”)を評価するために設計されたベンチマークです。
- 基礎的な概念の理解を問う
ARCのパズルは物体や境界、空間的関係といった基本的な概念を正しく把握する必要があります。単なる機械学習のパターンマッチングではなく、人間が持つ柔軟な認知能力を擬似的にテストできるよう工夫されています。 - “抜け道”対策
過去の大規模モデルは、膨大なサンプルを学習して「カバー率」を上げる形で性能を高めてきました。しかしARCは、そのような“トリック”を避けるために、限定的なトレーニングセットと、一般公開されていないテストセットを組み合わせています。さらに、課題を brute-force(総当たり)的に解かないよう、演算量に厳しい制限を設けています。
ARC-AGIは、こうしたARCの厳格な設計をもとに、「汎化性能」と「未知問題への適応能力」を測る、いわばAI研究の最前線を示す重要なチャレンジとなっています。
o3の驚異的な得点と、そこに至る道のり
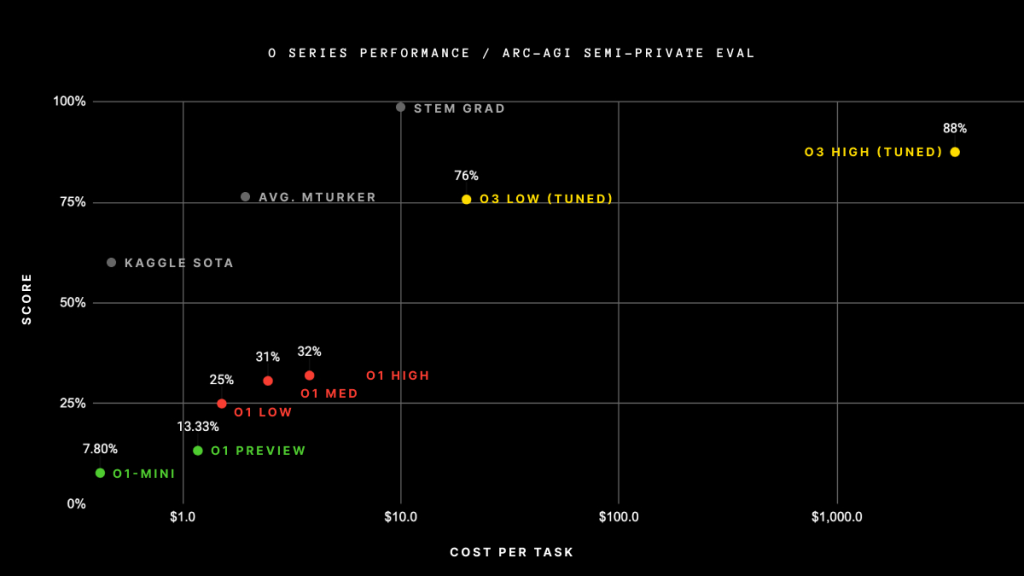
OpenAIのこれまでのモデル「o1-preview」や「o1」は、ARC-AGIでの最高スコアが32%ほどにとどまっていました。
研究者Jeremy Berman氏が開発した「Claude 3.5 Sonnet」と遺伝的アルゴリズム、コードインタプリタを組み合わせたハイブリッド手法が53%を記録していましたが、それでもスコア的には限定的でした。
未知タスク適応力が、明らかに新たな段階に達した
ところが今回のo3では、一気に75.7%(低演算量設定)から87.5%(高演算量設定)という記録的な数値を叩き出し、研究者たちを驚嘆させています。
ARCの開発者であるFrançois Chollet氏もブログで「これまでのGPT系モデルが苦手とした未知タスク適応力が、明らかに新たな段階に達した」と評価。4年間かけてもほぼ0%から5%程度しか伸びなかった点数が、わずかな期間で大幅に進歩したことについて、「量的な改善ではなく質的転換を示す」と述べています。

依然として高コストな推論
一方で、o3はその推論に要する計算コストの大きさが課題として指摘されています。低演算量設定の推論ですら、1問につき約33百万トークン(約17~20ドル相当)が必要です。
高演算量設定では約172倍ものリソースを投入しており、推論1回ごとの費用もさらに跳ね上がります。ただ、AI推論コストは年々急速に低下しており、今後の技術進歩次第では“高価な実験”がより身近になっていく可能性もあります。
「プログラム合成」がカギ?議論が沸き起こる推論アプローチ

o3がARC-AGIで高いスコアを出せた背景には、「チェーン・オブ・ソート(CoT)」や「プログラム合成」のアプローチがあるのではないかと推測されています。
プログラム合成とは
プログラム合成とは、小さなサブルーチン(プログラム)を作り、それらを組み合わせて複雑な問題を解決していく手法です。
クラシックなLLMは膨大な言語データを学習することで「内部的なプログラム」を獲得していると言われていますが、これまでのモデルは必要なコンポーネントを柔軟に“合成”できないという難点がありました。
- Chollet氏の仮説
CoT推論と探索メカニズム、報酬モデルを組み合わせ、逐次的に出力を生成しながら解を改善していくアプローチがo3の秘密なのでは、とChollet氏は推測しています。 - RL(強化学習)拡張説
研究者Nathan Lambert氏(Allen Institute for AI)は、o1やo3が「単一の言語モデルの順伝播推論(forward pass)かもしれない」と指摘。OpenAIの研究者Nat McAleese氏も「o1は単に強化学習(RL)で学習されたLLM。o3はさらにRLを拡張して強化したもの」と語っています。 - 「探索」批判
一方でGoogle DeepMindのDenny Zhou氏は、LLMの推論に検索(MCTSなど)を組み合わせる手法を「行き止まり」と呼び、トークンを逐次生成する“オートレグレッシブ”手法こそが真髄だ、と主張。AIコミュニティでは新たな推論パラダイムをめぐる議論が白熱しています。

「ARC-AGI=AGI」ではない
ARC-AGIという名称により、今回の成果をもって「AGI(汎用人工知能)の誕生か?」と話題になることもありますが、Chollet氏は「ARC-AGIを攻略すること自体はAGIの到達を意味しない」と強調しています。
たとえばo3は、非常に簡単な問題をときどき失敗することが観察されており、人間の知能とは依然として異なる側面があるとのことです。
また、現状のo3は外部の検証機構や、人間がラベル付けした思考過程(Chain-of-Thought)に依存しているともいわれています。
研究者Melanie Mitchell氏は、ARCのトレーニングセットを使って微調整(ファインチューニング)している点を問題視し、「本来は未知のドメインや類似タスクでも柔軟に適応できるかを検証すべきだ」とコメントしています。
次の評価手法、そしてAGIへの道

Chollet氏らは現在、o3でも得点が30%未満にまで落ちるような新ベンチマークの作成に取り組んでおり、人間ならば95%以上簡単に解けるテストになるとしています。人間にとっては直感的で容易だがAIには困難──こうしたギャップを埋める作業が、AGI研究の当面の課題として続くでしょう。
Chollet氏は「もし、人間にとって容易なタスクを設計してもAIにとって非常に難しい問題を作れなくなる日が来たとしたら、それがAGI到来のサインだ」と述べています。o3のARC-AGI攻略は、確かに歴史的な進歩ですが、AIが“汎用知能”に至るには、まだ多くの「未知」が存在するというのが総合的な見解です。
OpenAIは具体的なモデル内部の構造を公表していませんが、こうした新たな推論アプローチによる大幅な性能向上が「LLMの次なるパラダイムシフト」につながる可能性も否定できません。今後の技術的検証や、より厳密なベンチマークが進めば、新たな大規模モデル開発の方向性が見えてくるでしょう。
まとめ:最新のo3が導くAIの未来

最新のo3が示したAI推論の進歩は、単なるスコア向上にとどまりません。未知タスクへの柔軟なアプローチや、探索・合成型推論への関心を引き上げ、研究者コミュニティに新たな“突破口”が見えたとも言えます。
一方で、ARC-AGIという一指標のクリアが、AGI到達を即意味するわけではないことも、識者のあいだで共通認識となっています。
AI推論の次のステップがどのような形で進化していくのか。プログラム合成や強化学習、そしてオートレグレッシブ生成のそれぞれのアプローチの行方を含め、私たちは引き続き注視していきたいところです。人類の長年の夢である「汎用人工知能」への道のりは、まさに今、大きく動き出しているのかもしれません。

参考)OpenAI’s o3 shows remarkable progress on ARC-AGI, sparking debate on AI reasoning
