

「自社データを外部に送信せずに生成AIを活用したい」「APIコストを削減したい」「インターネット接続なしでも使えるAIが欲しい」
こうしたニーズに応えるのが「ローカルLLM」です。クラウドサービスを介さず、個人のPCや企業のサーバーなどのローカル環境で直接動作する生成AIモデルとして、近年急速に注目を集めています。本記事では、ローカルLLMがもたらす5つの具体的なメリットと、実際の導入方法、そして注目の日本語対応モデルまで徹底解説します。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
クラウド不要!ローカルLLMが切り開く未来とは?
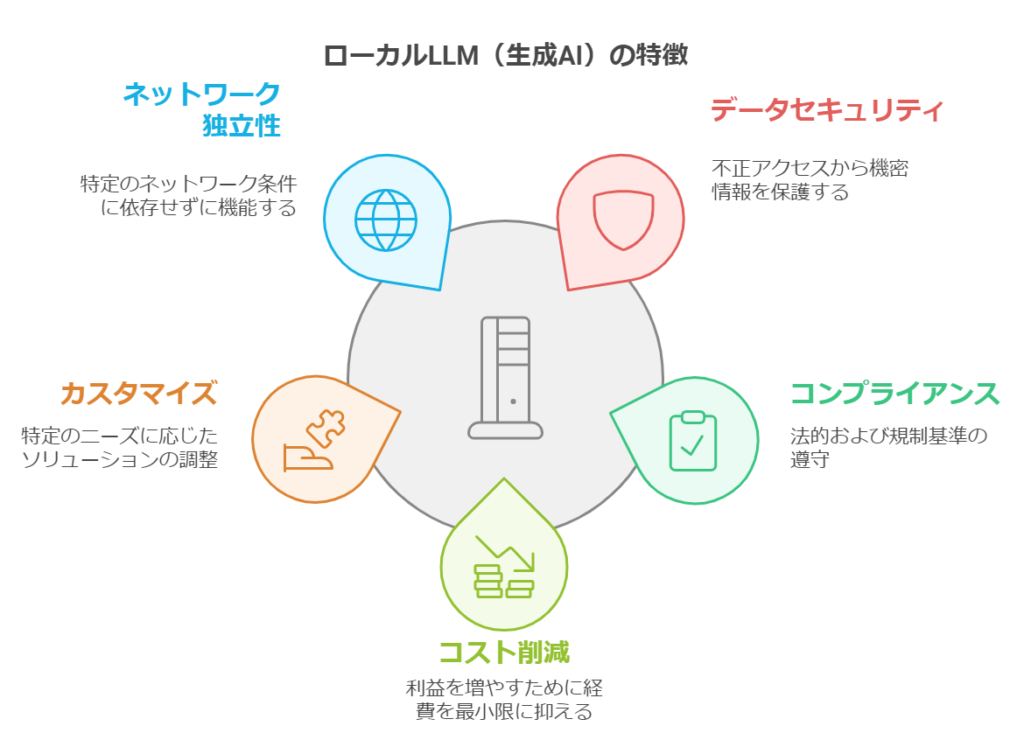
ローカルLLMの最大の特徴は、ネットワークに接続せずに個人のPCや企業のサーバーなどで直接、生成AIを活用できる点です。この「オフライン性」から生まれる5つの重要なメリットを見ていきましょう。
- データのセキュリティとプライバシーの強化
- コンプライアンス要件への対応
- コスト削減
- カスタマイズ性の向上
- ネットワーク環境に左右されない
ローカルLLMのメリット1: データのセキュリティとプライバシーの強化
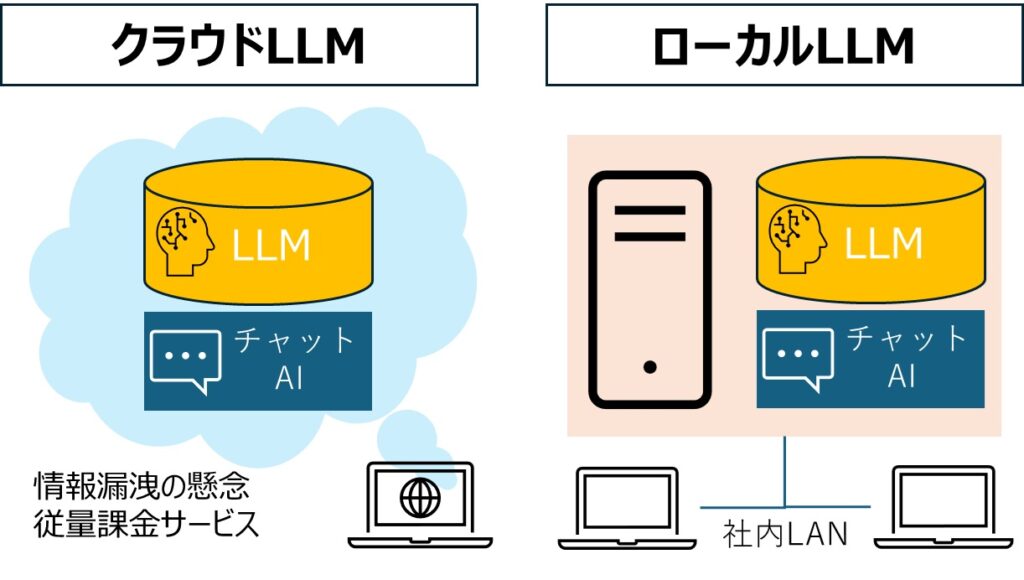
クラウド型の生成AIを使用する場合、常に情報漏洩のリスクが懸念されます。機密情報や個人情報を含むデータを外部サーバーに送信することに抵抗を感じる企業や個人は少なくありません。実際、多くの企業ではこのセキュリティリスクを理由に生成AIの利用を制限しています。
ローカルLLMでは、すべてのデータ処理が自社環境内で完結するため、このセキュリティリスクを根本から解消できます。
ローカルLLMのメリット2:厳格なコンプライアンス要件にも対応可能
セキュリティの観点から一歩進んで、業界固有のコンプライアンス要件にも対応できる点がローカルLLMの強みです。取引先が生成AIの利用を禁止している場合でも、データを外部に送信しないローカルLLMであれば、取引先の承認を得られる可能性が高まります。
ローカルLLMのメリット3:コスト削減
一般的にクラウド型の生成AIは、利用量に応じてAPI料金が課金されます。そのため、大量のデータ処理を行う場合は、高額な費用が発生してしまう可能性もあるのです。
ローカルLLMならデータ送信自体を行わないため、当然データ処理による料金は発生しません。初期費用こそかかりますが、大幅にランニングコストを抑えられる可能性があります。

ローカルLLMのメリット4:業務に特化したカスタマイズが可能
ローカルLLMの大きな魅力は、自社固有のデータを活用して精度を高められる点です。具体的には次の2つの方法があります。
- RAG(検索拡張生成)の実装:社内文書やナレッジベースをAIの参照情報として活用できます。AIはまず関連情報を検索し、その結果をもとに回答を生成するため、より正確で信頼性の高い情報を提供できます。
- ファインチューニング(追加学習):業界特有の用語や自社の業務フローに合わせてモデルを調整できます。
これにより、汎用的なAIでは難しい専門業務や社内特有の質問にも的確に対応できるようになります。
ローカルLLMのメリット5: ネットワーク環境に左右されない
大前提として、ローカルLLMはインターネットに接続していなくても利用できるため、ネットワーク環境が不安定な場所や、機密情報を含むデータを扱う業務でも安心して活用できます。環境によってですが、これだけでも十分なメリットがあると考えられます。
ローカルLLM(生成AI)の導入方法

ローカルLLMを導入することで、データのセキュリティ強化やカスタマイズ性の向上が期待できます。以下に、導入の基本的な手順を示します。
1.ハードウェアの準備
LLMは高い計算リソースを必要とするため、GPUを搭載した高性能なPCが推奨されます。ただし、近年ではCPUのみでも動作可能な軽量モデルも登場しています。
2.ソフトウェアのインストール
Pythonなどのプログラミング環境を整備し、必要なライブラリやツールをインストールします。たとえば、「llama-cpp-python」などのモジュールが利用されています。
3.モデルのダウンロード
Hugging Faceなどのプラットフォームから、目的に合ったLLMモデルをダウンロードします。日本語対応のモデルも増えてきています。
4.モデルの実行とテスト
ダウンロードしたモデルをローカル環境で実行し、動作確認を行います。適切なプロンプトを入力し、期待通りの出力が得られるかを確認します。
おすすめのローカルLLMソリューション
RAGを使って自社データを取り込み、ローカルLLMを活用したい方は、以下の情報をご覧ください。Pythonなどのプログラミング知識がなくても、オープンソースのLLMモデルをインストールすれば、自社内のPC上で生成AIを簡単に利用できます。

注目すべきオープンソースLLM「Gemma 2」

この記事では代表的なGoogleが開発したローカルLLMとして、Googleからリリースされている「Gemma 2」を紹介します。
Gemma 2の概要
Gemma 2は、Googleの最新LLMであり、9億、27億パラメータのモデルが公開されています。とくに、27億パラメータのモデル(Gemma2 27B)は、パラメータが2倍以上の他モデルに匹敵する性能を持つと報告されています。
Gemma 2の特徴と性能
Gemma 2は、以下の特徴を持ちます
- 高性能:主要なベンチマークで高い性能を発揮し、同規模の他モデルを上回る結果を示しています。
- 軽量性:モデルサイズが小さく、リソース効率が高いため、ローカル環境での実行が容易です。
- 商用利用可能:Apache License 2.0のもとで提供されており、商用利用が許可されています。
Gemma 2は日本語対応
特筆すべきは、日本語に特化したモデル「gemma-2-2b-jpn-it」の存在です。このモデルは、日本語での詩の作成や翻訳、コード生成など、多様なタスクで高い性能を発揮しています。
Gemma 2の導入方法
Gemma 2は、Hugging Faceのプラットフォームからアクセス可能で、以下の手順で導入できます:
- 環境構築:Python環境を整備し、必要なライブラリ(例:Transformers)をインストールします。
- モデルのダウンロード:Hugging Faceから目的のモデルをダウンロードします。
- 実行とテスト: ダウンロードしたモデルをローカル環境で実行し、動作確認を行います。
DeepSeekとLlama 4

中国のAI企業であるDeepSeekは、最新のAIモデル「R1」を公開し、その高性能と低コストで業界に大きな衝撃を与えています。 このモデルはオープンソースとして提供され、多くの開発者や企業が注目しています。
また、Meta社は、次世代のLlamaモデルである「Llama 4」の開発を進めており、100,000を超えるNvidia H100 GPUを使用した大規模なトレーニングを行っています。 2025年2月現在、まだリリースはされていませんが、2025年中には初期リリースされると予想されています。
その他のオープンソースLLM

オープンソースのLLMは無料で利用でき、カスタマイズ性が高いのが特徴です。以下に、日本語に強い代表的なモデルを8つ紹介します。
- Command R+
- ELYZA-japanese-Llama-2-7b
- Vecteus-v1
- Ninja-v1-RP-expressive
- Cohere’s Command R+
- ArrowPro-7B-KUJIRA
- RakutenAI-7B-Instruct
①「Command R+」:バツグンの安定性と高い日本語能力を持つAIモデル
Command R+は、AIスタートアップのCohereが開発した大規模言語モデル(LLM)で、エンタープライズ向けに設計されています。
高度な検索拡張生成(RAG)やツールの使用に特化しており、文書の要約や提供された情報に基づく質問応答、多言語対応など、ビジネスに必要なタスクで優れた性能を発揮します。
②「ELYZA-japanese-Llama-2-7b」:松尾研初のスタートアップが開発したモデル
ELYZA-japanese-Llama-2-7bは、株式会社ELYZAが開発した日本語特化の大規模言語モデルです。
Meta社のLlama 2をベースに、日本語データを追加学習し、指示追従能力を強化しています。

③「Vecteus-v1」:伸びしろがすごい日本語特化モデル
Vecteus-v1は、日本語に特化した大規模言語モデルで、今後の発展が期待されています。とくに、日本語の自然言語処理タスクでの高い性能に注目されています。
④「Ninja-v1-RP-expressive」:ローカルAIハッカソンから生まれたモデル
Ninja-v1-RP-expressiveは、ローカルAIハッカソンで開発されたモデルで、コミュニティ主導の取り組みとして注目されています。軽量で効率的なモデル設計が特徴です。
⑤「Cohere’s Command R+」:Cohereの原点であるAIモデル
Cohere’s Command R+は、Cohereが初期に開発した大規模言語モデルで、ビジネス向けのタスクに特化しています。文書の要約や質問応答などで高い性能を示しています。
⑥「ArrowPro-7B-KUJIRA」:現役高校生が作った日本語特化のAIモデル
ArrowPro-7B-KUJIRAは、現役高校生が開発した日本語特化の大規模言語モデルで、その独創性と技術力が評価されています。
⑦「RakutenAI-7B-Instruct」:楽天グループが開発したAIモデル
RakutenAI-7B-Instructは楽天グループが開発した大規模言語モデルで、7億のパラメータを持ち、指示追従能力に優れています。楽天のサービスにおける多様なタスクでの活用が期待されています。
注目が集まるローカルLLM(生成AI):まとめ

ローカルLLMの導入は、データのセキュリティ強化やカスタマイズ性の向上など、多くのメリットをもたらします。適切なハードウェアとソフトウェアの準備、そして目的に合ったオープンソースLLMの選択を通じて、効果的な活用が可能となります。今後も技術の進化に伴い、ローカルLLMの活用範囲はさらに広がることが期待されます。

