

クラウドAIサービスの高額な利用料や、データプライバシーの懸念から解放されたいと思いませんか?本記事では、Meta社が開発した高性能な大規模言語モデル「Llama」を、インターネット接続なしで自分のPC上で動かす方法を解説します。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
ローカルLLMとしてLlamaモデルを動かすために
LM Studioというユーザーフレンドリーなツールを使えば、技術的な知識が少なくても、わずか4ステップでローカルAIアシスタントを構築できます。オフライン環境での作業や、機密データを扱う場合でも安心して利用できる環境を整えましょう。Llamaとは、Meta社が開発した大規模言語モデル(LLM)であり、以下のような評価がされています。
- 高い自然言語処理能力: Llamaは、自然言語処理やテキスト生成において高い精度を持ち、対話や翻訳、コード生成など多様なタスクに対応できます。
- オープンソース化と商用利用: ソースコードが公開されており、商用利用が可能です。企業や開発者はモデルをカスタマイズし、独自のデータで学習させることができます。
- 多言語対応の進展: Llama 3は最大30言語、Llama 4は最大12言語をそれぞれサポートし、より広範なユーザー層に対応しています。
日本語での利用は可能?
初期のLlama 2は日本語学習データがわずか0.1%と少なく、日本語性能に課題がありました。しかし、現在では以下の選択肢があります。
- Llama 3:30言語をサポートし、日本語対応が大幅に向上
- 日本語特化モデル:ELYZA社の「Llama-3-ELYZA-JP-8B」や東京工業大学と産業技術総合研究所の「Llama 3.1 Swallow」など、日本語性能を強化したモデルが登場
つまり、適切なモデルを選べば、日本語でも十分実用的なレベルでLlamaを活用できるのです。
最新バージョンの進化
「Llama」シリーズの最新バージョン(2025年現在)「Llama 4」は、以下の特徴を持っています。
- Mixture of Experts(MoE)アーキテクチャ:複数の専門家モデルを組み合わせ、効率的な推論を実現。
- マルチモーダル対応:テキストと画像の入力に対応し、テキスト出力を生成。
- 長大なコンテキストウィンドウ:最大1,000万トークンの文脈を保持可能。
- 日本語にも対応:日本語を含む12言語に対応。
これらの特徴により、Llama 4は高度な推論能力と柔軟な応用性を兼ね備えたモデルとなっています。
LM StudioとLlamaモデルを動作させるステップ

ステップ1: システム要件の確認
LM StudioとLlamaモデルを効果的に動作させるためには、以下のシステム要件を満たしていることを確認してください。
- オペレーティングシステム
- Windows 10以降
- macOS 11.0以降
- Linux(Ubuntu 20.04以降推奨)
- ハードウェア
- CPU: AVX2命令セットをサポートするプロセッサ
- メモリ: 最低16GBのRAM(推奨: 32GB以上)
- ストレージ: モデルサイズに応じて数GBから数十GBの空き容量
- GPU: NVIDIA製GPU(CUDA対応、VRAM 6GB以上推奨)
とくに大規模なモデルを使用する場合、十分なメモリとGPUリソースが必要となります。
ステップ2: LM Studioのダウンロードとインストール
システム要件を満たしていれば次に進みましょう。LM Studioのダウンロードとインストールです。
- 公式サイトにアクセス: LM Studio公式サイトにアクセスします。
- インストーラーのダウンロード:ページ上部の「Download」セクションから、お使いのOSに対応したバージョンを選択し、ダウンロードします。
- インストールの実行:ダウンロードしたインストーラーを起動し、画面の指示に従ってインストールを進めます。インストール完了後、LM Studioを起動します。
ステップ3: Llamaモデルのダウンロードとインポート
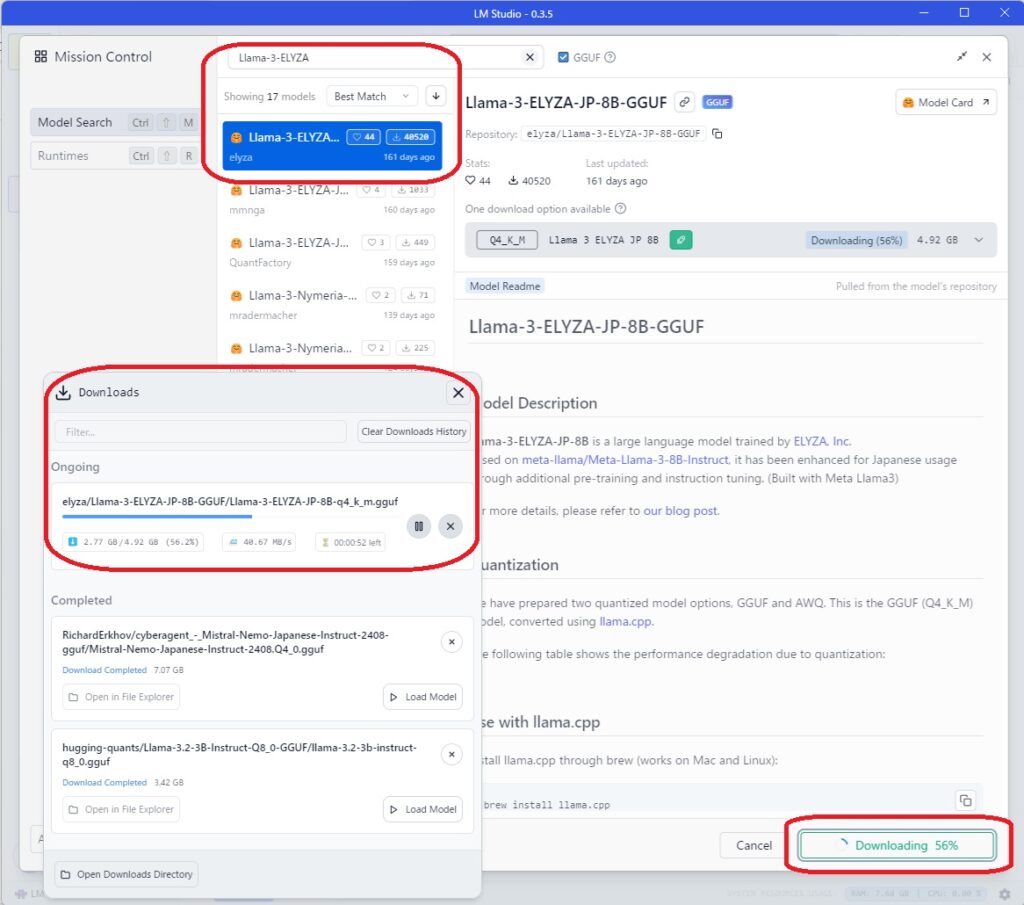
続いて、Llamaモデルのダウンロードとインポートを行います。
- モデルのダウンロード
- LM Studio内の「モデル」タブを開き、検索バーに「Llama」と入力して利用可能なモデルを検索します。
- 表示されたリストから、目的のLlamaモデルを選択します。モデルにはサイズや量子化形式(例: 7B、13B、30B、65B)があり、PCの性能や用途に応じて選択してください。
- モデルのインポート
- 選択したモデルの詳細ページで「ダウンロード」ボタンをクリックし、モデルのダウンロードとインポートを行います。
- ダウンロードが完了すると、モデルがLM Studio内にインポートされ、使用可能な状態になります。
ステップ4: モデルの設定と実行
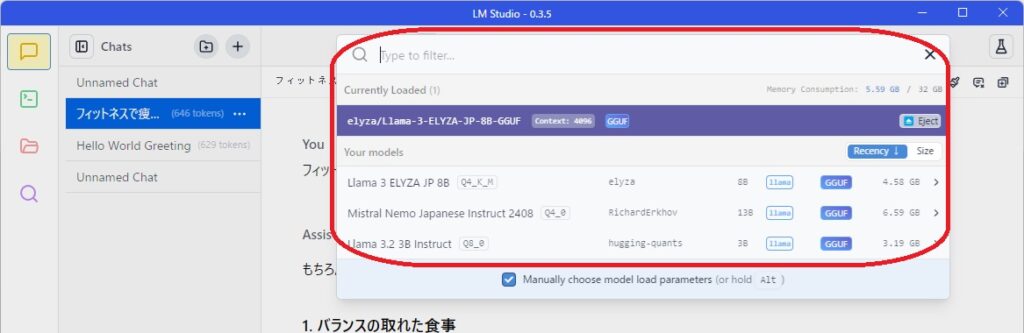
最後にモデルの設定を行えば、使えるようになります。
- モデルのロード
- LM Studioの「チャット」タブを開き、画面上部のモデル選択ドロップダウンから使用したいLlamaモデルを選択します。
- モデルがメモリにロードされるまで待ちます。
- 設定の調整
- 画面右側の設定パネルで、以下の項目を調整できます。
- GPU使用量: 「LOW」「50/50」「MAX」などから選択し、PCの性能や作業内容に応じて設定します。
- レスポンスの長さ: 生成されるテキストの長さを指定します。
- 温度: 生成されるテキストの多様性を制御します。
- 画面右側の設定パネルで、以下の項目を調整できます。
- チャットの開始
- チャット入力欄に質問や指示を入力し、Enterキーを押してモデルとの対話を開始します。
- モデルの応答が表示されるまで待ちます。
トラブルシューティング
最後に代表的なトラブルシューティングを紹介しておきます。
- モデルのロード(読み込み)に失敗する場合
- PCのメモリやGPUリソースが不足している可能性があります。より小さなモデルを選択するか、他のアプリケーションを閉じてリソースを解放してください。
- LM Studioの設定でGPU使用量を「LOW」に設定し、負荷を軽減してみてください。
- 応答が遅い場合
- モデルサイズを小さくするか、GPU使用量を「MAX」に設定してパフォーマンスを向上させてください。
また、LM Studioにはコミュニティフォーラム( LM Studio Community)もあります。
ローカル環境でLlamaを動かすステップ:まとめ

この記事ではローカル環境でLlama(オープンソースLLM)を動かすステップを紹介しました。この記事で紹介した手順どおりに行えば、Llamaの活用を始めることができます。
プライバシーを保護しながらオフラインでのAIモデルの活用をしたい方は、是非参考にしてください。

