
なぜいま音声文字起こしに注目すべきなのか
あなたは毎日どれだけの「声」を聞き逃していますか?
驚くべきことに、企業の会議では平均して60%の情報が記録されず失われているというデータがあります。また、85%のコンテンツクリエイターが、音声素材からの効率的な文字起こしが最大の課題だと回答しています。
本記事では、日本語を含む99言語に対応し、主要言語では95%以上の精度を誇るElevenLabsの新音声認識モデル「Scribe」の全容と、ビジネスやクリエイティブワークにもたらす可能性について、徹底解説します。
ElevenLabs「Scribe」とは何か

2025年2月26日、AI音声技術で知られるElevenLabsは音声認識モデル「Scribe」を正式発表しました。これまで主にテキストから高品質な音声を生成するサービスで知られていた同社が、逆方向となる音声からテキストへの変換(Speech to Text)領域に本格参入する意欲的な取り組みです。
Scribeの最大の特徴は、日本語を含む99言語に対応している点です。これは、FLEURSおよびCommon Voiceのベンチマークテストに基づいており、特にこれまでサポートが不足していたセルビア語、カントン語、マラヤーラム語などの言語でも高い精度を実現しています。
Scribeの機能紹介
Scribeの注目すべき機能として、以下の3点が挙げられます。
- 話者識別(Speaker Diarization): 最大32人の話者を区別し、「誰が」発言したのかを自動的に識別します。これにより、複数人参加の会議やインタビュー、ポッドキャストの文字起こしが格段に効率化されます。
- 文字単位のタイムスタンプ: 単語ごと、さらには文字レベルでのタイムスタンプを提供します。これによって、字幕の正確な同期やインタラクティブなオーディオ体験の構築が可能になります。
- 非発話イベントの処理: 笑い声、拍手、足音などの非言語音をタグ付けし、トランスクリプトに文脈情報として追加します。これにより、単なる「言葉」だけでなく、コミュニケーションの「雰囲気」も捉えることができます。
精度は言語によって異なる——日本語は「優秀」カテゴリに

Scribeモデルの精度は言語によって大きく異なります。ElevenLabsは言語ごとの精度を「ワードエラーレート(WER)」で分類しています。
WERとは、認識結果に含まれる誤りの割合を示す指標で、数値が低いほど精度が高いことを意味します。
精度カテゴリ別の言語分布
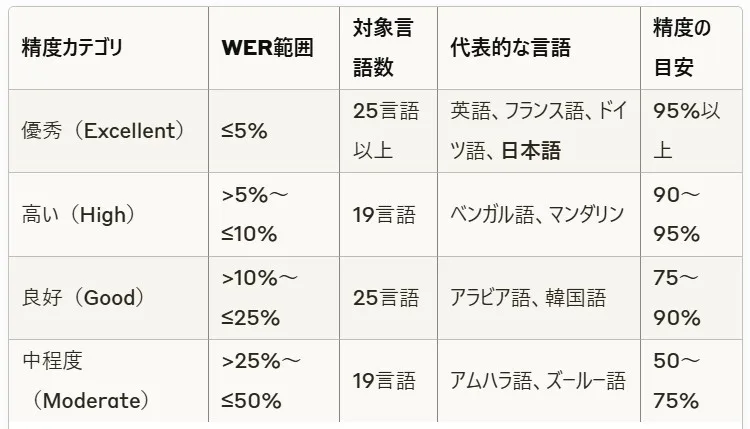
公式発表によると、英語では97%、イタリア語では98.7%の精度が報告されており、日本語も「優秀」カテゴリに分類されています。全言語の平均精度は約85.1%と推定されますが、これは中程度の精度しか達成できていない言語の影響を受けたものです。
実際の使用例として、ElevenLabsのブログでは日本語での認識例も公開されており、とくに単一話者の明瞭な発話では95%を超える高い精度が確認されています。一方、複数の話者が重なって話す場面や背景ノイズが大きい環境では、精度が若干低下する傾向があります。
競合サービスとの比較

音声認識技術の分野では、GoogleのGemini 2.0 Flash、OpenAIのWhisper Large V3、Deepgram Nova-3などが主要な競合として知られています。ElevenLabsの公式発表によれば、Scribeはこれらの競合モデルをベンチマークテストで上回る結果を示しています。
とくに注目すべき点は、これまでサポートが不足していた非英語圏の言語での精度向上です。例えば、Whisperと比較した場合、マイナー言語(セルビア語やマラヤーラム語など)での精度が平均10〜15%向上しているとのことです。
また、話者識別機能についても、Googleの音声認識サービスと比較して、より多くの話者(最大32人)を正確に区別できる点で優位性があります。
価格設定と利用方法
Scribeの価格は入力1時間あたり**0.40ドル(約60円)**と設定されています。これは、以下の方法で利用可能です:
- APIを通じた利用:開発者は、ElevenLabsのAPIを通じてScribeモデルにアクセスし、独自のアプリケーションに統合できます。API経由では、構造化されたJSON形式でレスポンスが返されるため、開発者にとって統合が容易です。
- UIを通じた直接利用:ElevenLabsのダッシュボードから直接、オーディオやビデオファイルをアップロードしてトランスクリプトを生成することができます。
現在はファイルベースの処理が中心ですが、近日中にリアルタイムアプリケーション向けの低遅延バージョンもリリース予定とのことです。これにより、ライブストリーミングや会議のリアルタイム文字起こしなども可能になると期待されています。
なお、医療機関や金融機関など、HIPAAコンプライアンスが必要な企業向けには、Business Associate Agreement(BAA)の署名が必要で、ElevenLabsのセールスチームに直接連絡する必要があります。
ビジネスユースケース:Scribeはどのように活用できるか

Scribeの登場により、さまざまな業界や用途での音声認識技術の活用が加速すると予想されます。具体的なユースケースとしては、以下のようなものが考えられます:
1. メディア・コンテンツ制作
- ポッドキャスト: エピソードの文字起こしと検索可能なアーカイブ作成
- 動画コンテンツ: 多言語字幕の自動生成
- インタビュー: 複数話者の識別と時間軸に沿った整理
2. ビジネス・企業向け
- 会議: 議事録の自動作成と重要ポイントの抽出
- カスタマーサポート: 通話記録の自動文字化と分析
- トレーニング: 教育コンテンツの文字化とナレッジベース構築
3. 研究・教育
- インタビュー調査: 質的研究のためのインタビューデータの文字起こし
- 講義: 授業内容の文字化とアクセシビリティ向上
- 多言語研究: 異なる言語での調査データの統一的な管理
特に日本においては、会議の議事録作成や外国語コンテンツの理解支援、海外向けコンテンツの多言語展開などの用途で、大きな効果が期待できます。
Scribeが示す音声認識技術の未来

Scribeの登場は、音声認識技術の新たな発展段階を示しています。とくに以下の3つの点で、今後のトレンドを予見するものと言えるでしょう:
1. 多言語・多文化対応の進化
英語中心だった音声認識技術が、より多様な言語や方言に対応することで、グローバルなコミュニケーションの障壁が低くなります。これは、とくにこれまでデジタルトランスフォーメーションから取り残されがちだった言語圏における情報アクセシビリティの向上につながります。
2. マルチモーダル理解の深化
Scribeが非発話イベント(笑い声や拍手など)も認識できることは、単なる「言葉」だけでなく、コミュニケーションの「文脈」や「感情」も含めた総合的な理解へと向かう流れを示しています。これは、より自然な人間-機械インタラクションの実現につながる重要な進歩です。
3. AIエコシステムの相互連携
ElevenLabsはこれまでText-to-Speech(テキストから音声への変換)で知られていましたが、今回Speech-to-Text(音声からテキストへの変換)も提供することで、双方向の変換が可能になりました。これにより、音声からテキストに変換し、編集後に再び高品質な音声に戻すといった、より柔軟なワークフローが実現します。

課題と今後の展望
Scribeの登場は大きな前進ですが、いくつかの課題も残されています。ElevenLabsは今後、以下の課題に対応するためのアップデートを継続的に行う予定とのことで、とくにリアルタイム処理の低遅延化と精度向上に注力するとしています。
- 方言や訛りへの対応: 特に日本語においては、標準語以外の方言や訛りに対する精度向上が今後の課題となるでしょう。
- 環境ノイズへの耐性: 実際のビジネス環境では、背景ノイズや音響条件が理想的でないケースが多く、そうした状況下での精度向上が期待されます。
- プライバシーとセキュリティ: 医療や法律など機密性の高い会話の処理における、データ保護とコンプライアンス対応の強化。
ElevenLabsの「Scribe」:まとめ

ElevenLabsの「Scribe」は、99言語に対応し、主要言語では95%以上の精度を実現する画期的な音声認識モデルです。話者識別、文字単位のタイムスタンプ、非発話イベントの処理など、先進的な機能を備えており、1時間あたり0.40ドルという比較的手頃な価格で利用できます。
音声コンテンツが増加の一途をたどる現代において、Scribeのような高精度な音声認識技術は、膨大な「聞こえる情報」を「見える情報」に変換し、検索可能で分析可能なデータとして活用する可能性を大きく広げるものです。

