

画像×文章で最先端!DeepSeek-VL2で広がるAI活用
最先端のAIが急速に進化する中、画像と自然言語を掛け合わせるマルチモーダル対応のモデルは、その活用範囲を一気に広げています。
この記事では大規模MoE構造を持つ最新技術「DeepSeek-VL2シリーズ」を徹底解説。画像解析や文書理解などで何ができるのか、そしてビジネスにどう役立つのかを知りたい方に最適です。
AI活用の意外な可能性に気づき、複雑な課題をスマートに解決するヒントを得られるでしょう。「大容量GPUが必須なのでは?」と不安を抱く方にも役立つ情報を盛り込みました。ぜひ最後までご覧ください。
DeepSeek-VL2シリーズとは
DeepSeek-VL2シリーズは、従来モデル「DeepSeek-VL」を大幅にアップグレードしたマルチモーダルAIモデルです。最大の特徴はMixture-of-Experts(MoE)アーキテクチャを採用している点で、画像と文章を統合的に処理し、高度な解析を可能にします。
視覚的質問応答(VQA)、光学文字認識(OCR)、ドキュメントやテーブル、チャートの理解、視覚的グラウンディングなど、多岐にわたるタスクで優れたパフォーマンスを示すことが報告されています。
本シリーズは活性化パラメータ数の異なる3つのモデルで構成されており、用途やリソースに応じて選択できる柔軟性が魅力です。
- DeepSeek-VL2-Tiny:1.0Bパラメータ
- DeepSeek-VL2-Small:2.8Bパラメータ
- DeepSeek-VL2:4.5Bパラメータ
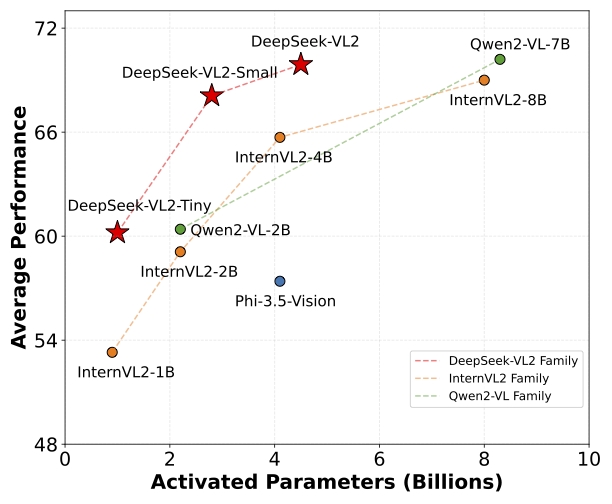
いずれのモデルも既存のオープンソース系のマルチモーダルモデルに比肩または凌駕する性能を示す一方で、同等または少ないパラメータで省メモリ化を実現している点が注目されています。
リリース情報とデモ
DeepSeek-VL2シリーズの開発チームは以下のように段階的にリリースを行っています。
- 2024-12-13:
- DeepSeek-VL2ファミリー初公開(DeepSeek-VL2-tiny、DeepSeek-VL2-small、DeepSeek-VL2)
- 2024-12-25:
- Gradioデモ例やIncremental Prefilling、VLMEvalKit対応を追加
- 2025-2-6:
- Huggingface Spaceで「deepseek-vl2-small」を用いたGradioデモを実装
Hugging Face上で各モデルをダウンロード可能であり、学術機関や企業など幅広いコミュニティでの研究・実装を想定しています。利用にあたってはライセンス規約の確認が必要です。
インストールと使い方
インストール手順
Python 3.8以上の環境が整っている場合、以下のコマンドを実行するだけで必要な依存関係がインストールされます。
pip install -e .
シンプルな推論例
1枚の画像を入力として推論を行う場合、たとえばdeepseek-vl2-smallを利用するには、およそ80GBのGPUメモリが必要とされています。より大きなモデルを扱う際は、それ以上のメモリが必要になる点に注意が必要です。少ないリソースで試してみたい場合はDeepSeek-VL2-tinyを選ぶのも一案でしょう。
まとめ
DeepSeek-VL2シリーズは、画像認識や自然言語処理を単一のモデルで効率的にこなせる次世代型のマルチモーダルAIとして期待されています。大規模なパラメータを抱えながらも、用途や環境に合わせた最適なモデルサイズを選ぶことが可能です。
グラフィカルなデモも用意されており、実際に触れてみることでその性能を直感的に理解できるでしょう。今後も継続的にアップデートが行われる見込みのため、最新情報を追いかけて損はありません。
参考)Chat with DeepSeek-VL2-small
