

中国のAI企業・DeepSeekが新たに公開した超大規模AIモデル「DeepSeek V3」が、世界のAI業界に衝撃を与えています。約6710億というパラメータ数を誇るこのモデルは、MetaのLlamaやOpenAIのGPTシリーズと真っ向から競合する存在として急速に注目を集めています。
特筆すべきは、このハイエンドモデルがオープンライセンスで公開されていることです。これにより、世界中の開発者が自由に研究・改変・商用利用できる環境が整いました。本記事では、DeepSeek V3の実力、日本語での使い方、そして他の主要AIモデルとの比較を詳しく解説します。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
オープンAIモデルの新たな雄「DeepSeek V3」とは
1. 圧倒的なスケール
- パラメータ数: 約6710億(Hugging Face上では6850億とも表記)
- 学習データ量: 約14.8兆トークン
AIの性能はモデルサイズ(パラメータ数)と学習データ量に大きく依存します。DeepSeek V3のパラメータ数はMetaの「Llama 3.1 405B」(4050億パラメータ)と比較して約1.6倍の規模を誇ります。また、学習に使用されたデータ量も14.8兆トークンという膨大なボリュームに達しています。この圧倒的なスケールが、DeepSeek V3の高い処理能力と多様なタスクへの対応力を支えています。

2. 豊富な機能と高い汎用性
DeepSeek V3は、以下のようなタスクに対応できるとされています。
- プログラミングのコード生成・修正
- ウェブ検索による情報収集
- 思考を必要とする複雑な問題解決(R1モード)
- 翻訳
- 文章作成(エッセイやメール文など)
DeepSeekの社内ベンチマークによると、人気のプログラミング競技プラットフォーム「Codeforces」上でのコンテスト課題をはじめ、複数のテストで高いスコアを記録。
大規模モデルとして提供されるだけでなく、オープンライセンスで公開されているため、多くの開発者が自由にダウンロードして研究・改変・商用利用できるのも大きな特徴です。
DeepSeekの使い方
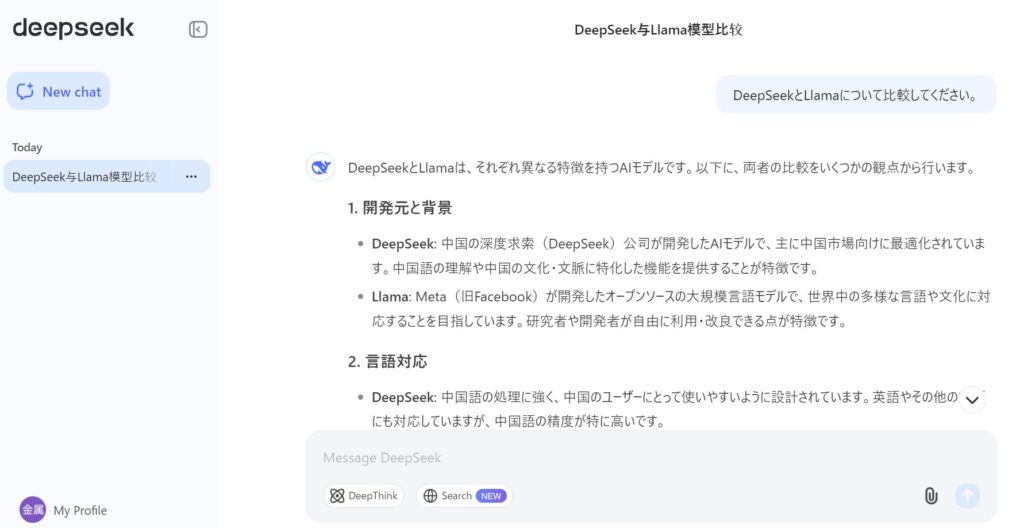
実際に試してみたところ、DeepSeekは日本語でも十分に使えました。「DeepSeekとLlamaについて比較してください。」と質問すると、日本語でスピーディーに回答が表示されます。
また、DeepThink(R1モード)というモードがあり、こちらをONにして、「日本の30年後の人口は?」と質問したところ、10秒ほど考えた結果、以下のような回答がありました。
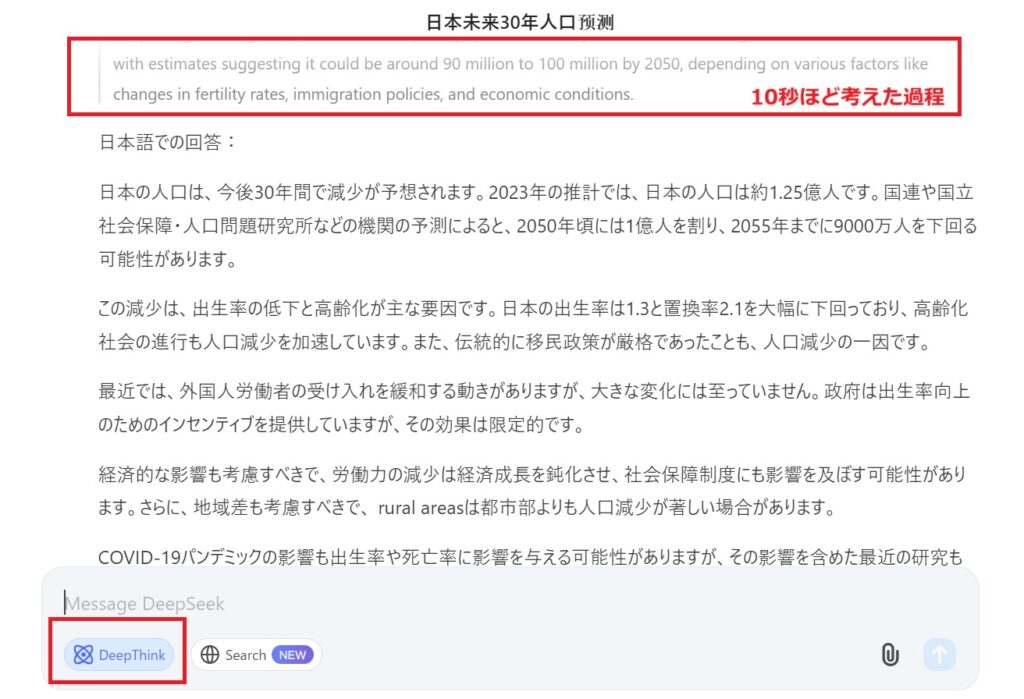
日本の人口は、今後30年間で減少が予想されます。2023年の推計では、日本の人口は約1.25億人です。国連や国立社会保障・人口問題研究所などの機関の予測によると、2050年頃には1億人を割り、2055年までに9000万人を下回る可能性があります。・・・・
DeepSeekはWeb検索にも対応
最新情報を調べたり、その情報をもとに文章を作成したりする際には、Web検索機能がとても便利です。
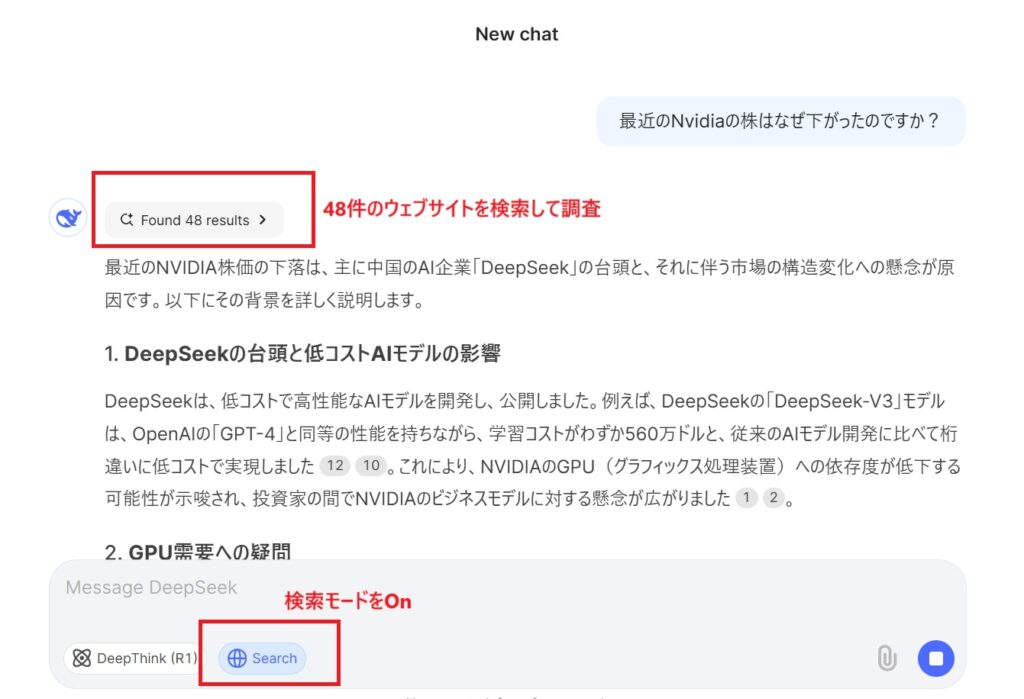
たとえば「最近、Nvidiaの株価が下がった理由は?」と質問すると、48件のウェブページをリサーチして答えを提示してくれました。この記事を執筆している時点で、株価の下落は2~3日前に起きたものです。つまり、最新の情報を検索し、それをもとに回答を作成してくれるのです。
DeepSeekのスマホアプリでも問題なく日本語が使える
DeepSeekのスマートフォンアプリは日本語に対応しており、問題なくご利用できます。iPhone用のAIアシスタントアプリ「DeepSeek」は、バージョン1.0.4から日本語対応が開始されました。
App Storeの情報によれば、アプリは日本語を含む複数の言語に対応しています。また、R1モデルや検索機能もご利用できます。
他社モデルとの比較—性能は「GPT」や「Llama」を凌駕?

DeepSeek V3は、以下のいくつかの強力なモデルに勝る場合があると報じられています。
- MetaのLlama 3.1 405B
- OpenAIのGPT-4o
- AlibabaのQwen 2.5 72B
とくに「Aider Polyglot」というコード統合に関するテストでは、既存モデルと比較してDeepSeek V3が抜きんでた成果を示しているとのことです。もっとも、AIベンチマークは各社独自のテスト方法や条件設定が異なるため、客観的な比較には第三者の検証が欠かせません。
低コスト&短期開発の実現—Nvidia H800で2か月・5.5百万ドル

DeepSeekは、モデルのトレーニングに約2か月・費用は550万ドル(約8億円)ほどしかかからなかったと主張しています。
- ハードウェア: 中国・Memphis拠点のNvidia H800 GPUを活用
- 期間: 約2か月
- コスト: 550万ドル
同規模の大規模モデルを開発する際は1億ドル単位の費用がかかることも珍しくありません。たとえばOpenAIのGPT-4の開発費用は数億ドル規模とも言われています。DeepSeekはこのコスト削減と高速開発を大きなアピールポイントとして掲げています。
ただし、Nvidia H800は米国商務省の輸出規制により、中国企業の入手に一定の制限がかかっているはずのGPUです。そうした規制のなかで、どうやって大規模なGPUクラスターを維持し、大量のパラメータを短期間で学習させたのかは気になるところといえます。

政治的バイアスとコンテンツ規制
DeepSeek V3には、政治的・社会的にセンシティブな質問に対する回答を制限する仕組みが存在します。中国のインターネット規制当局は、生成AIの出力が「社会主義コアバリュー」を反映しているかどうかを厳しく監視しており、以下の振る舞いが見受けられます。
- 天安門事件に関する質問に回答しない
- 習近平政権を批判するようなトピックを避ける
この点は、国際的なオープンソースコミュニティの期待する“自由な対話と情報アクセス”とは相容れない部分もあるかもしれません。今後、海外での利用を想定するユーザーや企業にとっては、実装時の「検閲」回避策などが課題となり得ます。

DeepSeekは自分のパソコンでも動かせる?
DeepSeekはお使いのパソコンでも動作させることが可能です。特に、DeepSeekが提供する軽量モデル「DeepSeek-R1-Distill」シリーズは、一般的なPCや古いCPU環境でも動作するよう設計されています。ローカル環境で動かせば、情報漏洩のリスクを大幅に低下させることができます。詳しくはこちらの手順を参考にしてください。
DeepSeekの資本背景—High-Flyer Capital Managementとは
DeepSeekは、主に中国のヘッジファンド「High-Flyer Capital Management」から資金提供を受けています。
- High-Flyer: AIを活用したトレーディング手法で成功を収めているファンド
- サーバー投資: 自社で1,000台以上のNvidia A100 GPUを備える大規模クラスターを構築したとの報道(約100億円超)
High-Flyerの創業者である梁文峰(Liang Wenfeng)氏は、「クローズドソースAI(OpenAIのような商業機密の塊)はあくまで一時的な参入障壁にすぎない」と強調しています。オープンかつ大規模なAIモデルを用意することで、最終的には多くのプレイヤーが競合に参加できる未来を想定しているようです。

まとめ:超大規模オープンモデルの可能性と課題

- 超大規模・オープンソース:
- 6710億パラメータという規模を誇るDeepSeek V3は、世界のAIコミュニティに新たな選択肢を提供し得る存在。
- 低コスト・短期間:
- わずか2か月、550万ドルで開発可能だったという点は他社にとって驚きの事例。
- 中国的規制・政治的バイアス:
- 対話内容や応答が検閲される可能性が高く、グローバルでの普及には課題も。
パラメータ数や学習データ量が増大する一方で、コスト面・規制面・性能面のハードルもますます高くなる時代。DeepSeek V3が本当に「OpenAIやMetaのライバル」として活躍し得るのか、その真価が問われるのはこれからでしょう。
今後は国際的なコミュニティがこのモデルをどのように検証・評価し、“オープンで超大規模”の強みを活かせるかが大きな焦点となりそうです。

参考)DeepSeek公式ページ、DeepSeek’s new AI model appears to be one of the best ‘open’ challengers yet

