

もし小型モデルでも十分な性能を確保でき、かつ企業や開発者にとって扱いやすい大規模言語モデル(LLM)でのAI活用の選択肢があるとしたらどうでしょう?
この記事では、Googleが新たに公開した小型言語モデル「Gemma 3」の魅力と、そのビジネス活用におけるメリットを詳しく解説します。
量子化で進化したGoogle『Gemma 3』の秘密

近年、大規模言語モデル(LLM)が登場し、AIを活用した高度なテキスト生成や推論機能は世界的に注目を集めています。しかし、その一方で学習や推論に大きな計算リソースが必要となり、エネルギーやコスト面で導入に二の足を踏む企業や開発者が少なくありません。
そこで浮上しているのが、エッジデバイスや個人レベルでも利用しやすい「小型言語モデル(SLM)」という選択肢です。Googleはこの流れを後押しするかのように、より小型でありながら高い性能を持つ言語モデル「Gemma」シリーズを提供してきました。
そして今回、新バージョンとなる「Gemma 3」が発表され、その性能と汎用性の広がりが話題を集めています。
Gemma 3の特長:128Kの巨大なコンテキストウィンドウ
まず注目したいのは、「Gemma 3」が128Kという大きなコンテキストウィンドウを備えている点です。前バージョンである「Gemma 2」では80Kでしたから、大幅な増強といえるでしょう。
コンテキストウィンドウが大きいほど、一度に把握・処理できる情報量が多くなります。これによって、複雑な依存関係を含む長文の解析や、複数のデータを同時に取り扱うタスクへの対応力が飛躍的に高まります。大規模モデルと比べても遜色ない理解力を持ちながら、SLMならではの軽量さと取り回しの良さを併せ持つのが「Gemma 3」の大きな強みです。

複数サイズ展開:1Bから最大27Bパラメータまで
「Gemma 3」は、用途や使用環境に応じて1B、4B、12B、27Bという4種類のパラメータ規模が用意されています。大規模言語モデルとは違い、パラメータサイズを細かく選択できるのは大きな利点です。
小規模デバイスや個人のプロジェクトでは1Bや4Bを活用し、企業レベルのアプリケーションでは12Bや27Bを利用するといった柔軟な選択が可能になります。
また、どのサイズを選んでも、高度な自然言語処理やマルチモーダルな解析ができるようにチューニングされているのが特徴です。

マルチモーダル解析と140言語への対応
テキストだけでなく、画像や短い動画など、複数のモーダルを対象にできるのも「Gemma 3」の進化したポイントです。現代のビジネスシーンでは、SNS動画や画像広告、マーケティング資料など、メディア形式が多様化しています。それらのデータをひとつのモデルで横断的に扱えるのは、業務の効率化につながるはずです。
さらに、対応言語も140に拡大されています。多国籍企業やグローバル展開を視野に入れるチームにとっては、大きなアドバンテージになるでしょう。

性能向上のカギ:量子化モデル(Quantized Model)の導入
AIモデルを運用するコストを大きく左右するのが計算リソースです。高性能なGPUやクラウドリソースを常時確保するには、それなりの費用もかかります。
そこでGoogleが打ち出したのが「量子化(Quantization)」という手法です。量子化モデルでは、学習済みモデルのパラメータ精度を下げて圧縮しながら、性能への影響を最小限に抑えます。
こうした取り組みにより、より低コストの環境でも「Gemma 3」の高いパフォーマンスを生かせるようになりました。実際、単一のGPUやTPUホストで動作するアプリケーションを構築できるというメリットは、スタートアップから大企業まで幅広い層にアピールするでしょう。
大規模モデルに劣らない実力:Chatbot Arenaで好成績
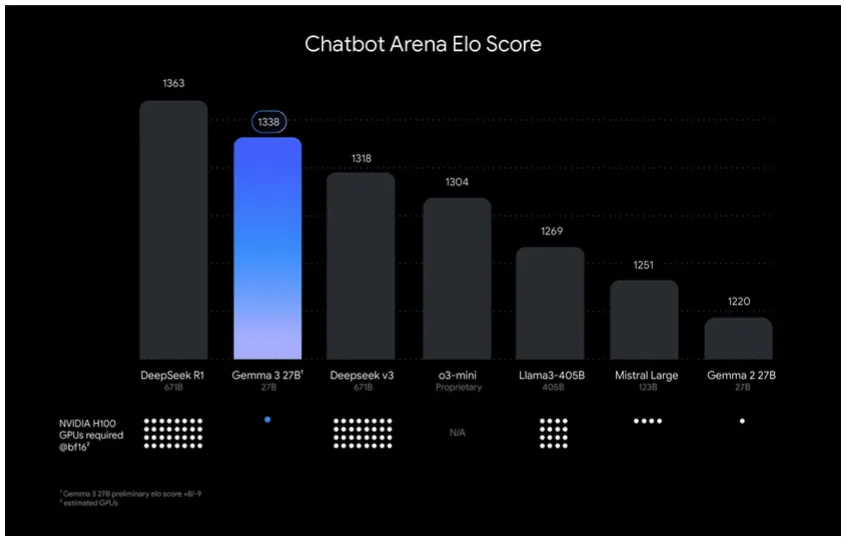
「Gemma 3」は小型モデルという位置づけにもかかわらず、その性能は大規模モデルにも匹敵します。
Googleの発表によれば、27Bパラメータの「Gemma 3」はChatbot Arena Eloスコアのテストで、他社のLLMである「Llama-405B」「DeepSeek v3」「o3-mini」「Mistral Large」を上回る結果を残しています。
総合ランキングでは「DeepSeek-R1」に次ぐ2位という好成績でした。大規模モデルを凌駕するまではいかないまでも、モデルサイズとコスト対効果を考慮すると非常に魅力的な選択肢となるでしょう。
豊富な開発ツールとの連携:Hugging FaceやPyTorchなど
開発者にとって見逃せないのが、「Gemma 3」がHugging Face TransformersやPyTorch、Keras、JAX、Ollamaなど、幅広いツールと連携しやすい点です。
すでに利用しているフレームワークやライブラリにスムーズに組み込めるため、新たなモデル導入へのハードルが下がります。
さらにGoogle自身が提供する「Google AI Studio」やKaggleを通じたアクセスも可能。クラウド環境を活用しての学習や推論が手軽に行えるようになり、開発速度の向上や実験サイクルの短縮が期待できます。
ShieldGemma 2によるセキュリティ機能
AIモデルが広く普及するにつれて、その安全性も無視できない課題となっています。Googleは「Gemma 3」のリリースに合わせて、画像に対する安全性チェックを行う「ShieldGemma 2」というモジュールを導入しました。
これは「Gemma 3」の技術を土台にした4Bパラメータのモデルで、性的・暴力的・その他不適切な画像を判別し、応答を制限する役割を果たします。
企業ごとのポリシーに合わせて調整できるカスタマイズ性もあり、安心してAIを活用した画像処理や分析を実装できるでしょう。

小型モデルや蒸留モデルへの関心の高まり
「Gemma」シリーズが注目を浴びている背景には、全体として小型モデルや蒸留モデルへの需要が高まっているという事情があります。大規模モデルをまるごと運用するのは、多くの企業にとって高コストであり、機能を持て余すケースもしばしばです。
そこで、性能を最適化しつつ軽量化を図る「蒸留(Distillation)」や、そもそも小型設計でトレーニングされたモデルに目が向けられています。Gemmaシリーズは「Gemma自体がGemini 2.0の蒸留版ではない」とされつつも、同じアーキテクチャを用いて比較的コンパクトに設計されている点で、大規模モデルより手軽な選択肢といえるでしょう。
企業導入のポイント:適切なタスクへのアサイン
「大規模モデルをそのまま導入するとオーバースペックになりがち」「高性能なモデルが必要なタスクは限られている」と感じている方には、小型モデルや蒸留モデルの活用が合理的です。
とくに、コード補完や特定分野の文章校正など、比較的シンプルなタスクであれば、大規模モデルをわざわざ使わなくてもGemma 3のようなSLMで十分に用が足ります。
結果として、導入費用やハードウェアコストの削減につながる可能性が高く、企業のROI(投資対効果)を大きく高める選択肢となるでしょう。
Gemma 3:まとめ

今回の「Gemma 3」の発表は、AI分野におけるGoogleの先進性と、“大規模モデル一辺倒ではない”新たな戦略を強く印象づけるものでした。
128Kという大容量のコンテキストウィンドウと多様なサイズ展開、そして量子化モデルやセキュリティ機能などを統合した「Gemma 3」は、個人・企業問わずさまざまなユーザーにとって魅力的な選択肢となり得ます。今後ますます競争が激化していく言語モデル市場で、軽量・高性能・安全性の三拍子が揃った小型モデルがどのように進化し、普及していくのか注目です。

