

自社データや外部データをChatGPTで活用するには?
近年、大規模言語モデル(LLM)の飛躍的な進化により、自然言語処理(NLP)分野は急速な変革を遂げています。その中でも、OpenAIが開発したChatGPTは、人間に近い自然言語応答能力と高度なタスク適応性を備えたモデルとして注目を集めています。
一方で、実運用環境においては大規模モデル単体では必ずしも十分な精度・一貫性を確保できない場合もあり、外部知識へのアクセスや特定ドメイン情報との統合が求められています。
このような要請に応える手法として注目されているのが「Retrieval-Augmented Generation(RAG)」です。RAGは事前学習済みモデルと外部知識ベースとの連携により、より正確かつコンテキスト依存性の高い応答やテキスト生成を可能とします。本稿では、ChatGPTおよびRAGの概要や、両者が組み合わさることで得られる価値、実際の適用領域や課題について、専門的な観点から考察します。
ChatGPTの特長と課題
ChatGPTは、Transformerアーキテクチャをベースとした大規模言語モデルであり、膨大なテキストコーパスで事前学習されています。その結果、一般的なタスクに対する高い自然言語理解能力や文脈理解に優れ、幅広い分野での会話的インタラクションが可能です。
しかしながら、ChatGPTは固定されたパラメータ内に知識を内包しており、学習後に新たな情報やドメイン固有知識を取り込むことが困難です。そのため、最新情報や特定領域の専門知識を必要とする場合、単体では最適な応答を必ずしも得られません。特に、モデル構築をした後に出現した最新情報に対しては弱く、信頼性のあるソースへのアクセスが求められる状況も多く見られます。
RAGとは?仕組みと概要
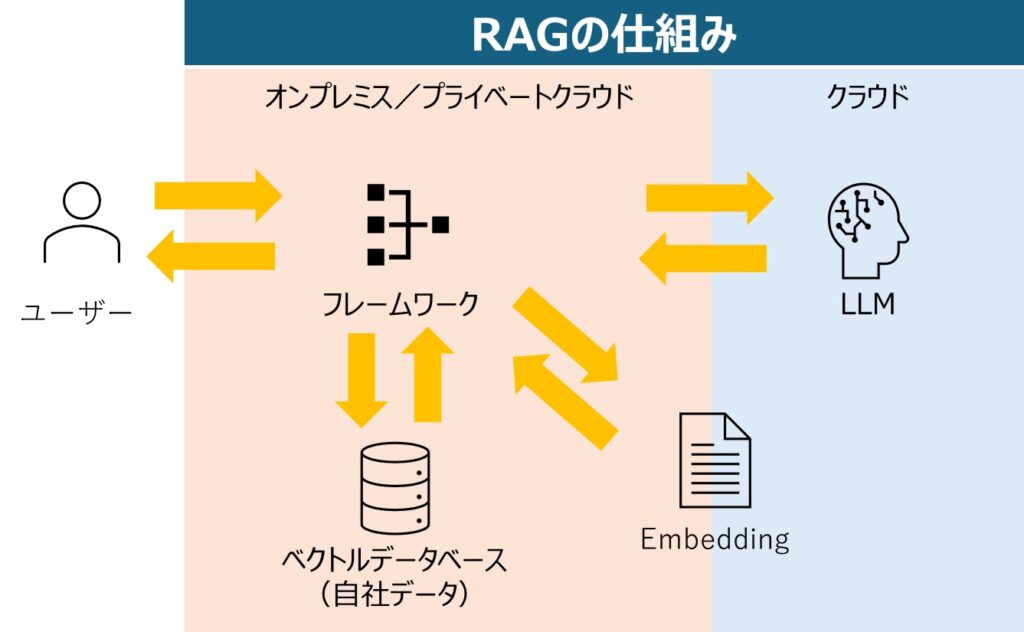
RAGとは、言語モデルへの問合せ時に外部の知識ベースやドキュメントを動的に参照し、その取得情報をもとにテキスト生成を行う手法です。具体的には、以下のような手順が一般的です。
- クエリ拡張・処理:
- ユーザーからの質問や指示を適宜前処理し、検索に適した形式に整えます。
- 情報検索:
- 外部データベース、検索エンジン、あるいはベクトルデータベース(Embeddingを用いた類似検索)を用いて、関連するドキュメントや知識片を取得します。
- 言語モデルによる統合生成:
- 取得した情報をプロンプトとして言語モデルに与え、回答やテキストを生成します。これにより、モデル本体が持つ内部知識と外部の最新・詳細な情報を組み合わせた、高品質な回答が可能になります。
ChatGPT × RAG のシナジー

ChatGPTとRAGの組み合わせは、ユーザの要求に柔軟に対応できる強力なフレームワークを形成します。ChatGPTの言語生成能力とRAGによる外部知識補強は以下の点で有用です。
- 最新情報へのアクセス:
- 最新のニュース、業界動向、研究結果などを外部リソースから取得し、アップデートされた内容を反映した回答を生成可能。
- 業界特有な情報・知識の柔軟な適用:
- 医療、金融、法務、テクニカルサポートなど、特定ドメインの専門文献やFAQドキュメントを動的に取り込み、的確な応答を提供。
- モデルサイズ・学習コストの低減:
- モデル自体を大きくすることで内部知識を拡張する手法と比較して、RAGは必要な知識を「外部化」することでパラメータ数を抑制し、再学習コストを低減可能。
ChatGPTとRAG構築のステップ

以下では、ChatGPTとRAGを組み合わせたシステムを構築する際の一般的な手順を、技術的な観点からステップバイステップで解説します。なお、実際の実装は使用するインフラ(クラウド環境やオンプレミス環境)、利用するツール(特定のベクトルデータベースや検索エンジン)、言語モデルのAPI提供形態によって異なりますが、ここでは汎用的なフレームワークとしてまとめます。
ステップ1:要件定義とドメイン選定
- ユースケースの明確化:
- 対話型アシスタント、FAQボット、ドキュメント要約ツールなど、RAG適用対象のユースケースを明確にします。
- ドメインの範囲設定:
- 医療、法律、技術サポート、金融など対象ドメインを定め、必要な外部知識ソースを選定します。
ステップ2:外部知識ソースの選定・準備
- ソース収集:
- ウェブページ、社内ドキュメント、学術論文、製品マニュアル、FAQリストなど、対象分野に適した知識ソースを収集します。
- データクリーニング:
- 重複・冗長情報の削除、フォーマット統一、不要なHTMLタグの除去、表や図など非テキスト情報の取り扱い(テキスト化可能ならOCRや変換処理)を行います。
- メタデータ付与:
- 文書ID、日付、著者、タグなどのメタ情報を整理・付与しておくと、検索精度向上や情報トレーサビリティ確保に有用です。
ステップ3:ベクトル化とインデキシング
- 埋め込みモデル(Embedding Model)の選定:
- OpenAI Embeddings、Sentence-BERT、Cohere Embeddingなど、ドメインに適合し、品質が高い埋め込みモデルを選びます。
- テキスト分割(Chunking):
- 文書を一定長または文脈単位(段落など)で分割します。短すぎるとコンテキスト不足、長すぎると検索精度低下の懸念があるため、適度なサイズに分割することが肝要です(例:1,000〜2,000トークン程度)。
- ベクトル変換:
- 各チャンクを選定した埋め込みモデルでベクトル表現(Embedding)に変換します。
- ベクトルデータベースへの格納:
- Pinecone、Faiss、Weaviate、Chromaなど、ベクトル検索用のデータベースにチャンクごとのベクトル情報をインデックスします。この際、メタデータ(文書ID、ソースURLなど)も併せて格納します。
ステップ4:検索機能の実装
- 検索APIの設計:
- ユーザからの問い合わせ(クエリ)に基づき、ベクトルデータベースへ類似検索を行うエンドポイントや関数を設計します。
- 類似度探索:
- クエリテキストを同様の埋め込みモデルでベクトル化し、ベクトルデータベース内で最近傍検索(近傍ベクトル探索)を実行します。
- 検索結果の取得:
- 得られた候補文書チャンクをスコア上位数件ピックアップします。一般的には3〜5件程度が妥当ですが、ユースケースに応じて調整可能です。
ステップ5:プロンプト合成(Prompt Engineering)
- テンプレート設計:
- ChatGPTへ渡すプロンプトは、ユーザのクエリと検索で得られたチャンク情報を適切に組み合わせる必要があります。
- 例: 「以下はユーザからの質問と関連文書です。関連文書を参照しながら、正確かつ根拠のある回答を行ってください。…」
- ChatGPTへ渡すプロンプトは、ユーザのクエリと検索で得られたチャンク情報を適切に組み合わせる必要があります。
- コンテキスト追加:
- 必要に応じてドメイン固有の手順や注意事項をプロンプトに書き込み、ChatGPTが解答時に考慮するようにします。
ステップ6:ChatGPT(LLM)への問い合わせと生成
- APIコール:
- 生成系LLM(ChatGPT APIなど)に対して、プロンプトを送信します。プロンプトには、ユーザの質問と検索で抽出した関連文書チャンク(あるいはその要約)を含めます。
- 回答生成:
- ChatGPTは受け取ったプロンプトを元に、外部知識を参照した回答テキストを生成します。
- 出力品質評価:
- モデルの応答内容が要求に合致しているか、信頼性があるかを検証します。不適切・不正確な回答が生じた場合は、プロンプトデザインや検索戦略の見直しを行います。
ステップ7:評価・改善
- テストと評価: RAGシステムが実際の問い合わせでどの程度正確な回答を生成するか、評価指標(回答の正確性、再現率、ユーザ満足度)を用いて定量的・定性的に評価します。
- 反復的改善: 評価結果に応じて、以下を継続的に改善します。
- 埋め込みモデルの切り替えや再学習
- 検索手法(類似度メトリクス、フィルタリング手法)の調整
- プロンプトテンプレートの最適化
- 新たな知識ソースの追加・更新
RAGの適用領域と事例
実務での適用事例としては、以下のようなケースが考えられます。
- カスタマーサポートチャットボットへの導入
- 企業内のドキュメント検索/要約システム
- 学術分野における文献検索アシスタント
- Eコマース分野では、ユーザ製品レビュー、在庫データ、マニュアル情報を参照しながら最適な製品レコメンデーションを行うシステム構築
今後の課題と展望
RAGを組み込んだシステムは、外部データの品質や更新頻度、検索精度に依存します。また、外部情報が偏りや誤りを含む場合、生成結果の信頼性に影響を及ぼします。これらの課題は、検証可能なソース確保、情報品質管理、モデル出力に対するファクトチェック機能の統合などで対応可能です。
将来的には、より高精度な情報検索技術や、LLMと知識グラフの緊密な結合、さらにはユーザのコンテキストや意図をより深く理解した動的なプロンプトエンジニアリング技術が発展することで、RAGを用いたChatGPTシステムはさらなる高度化が期待されます。
