

近年、ChatGPTのような大規模言語モデル(LLM)をパソコンやスマートフォンのローカル環境で動作させる「ローカルLLM」の普及が急速に進んでいます。
この記事では、ローカルLLMでのプライバシー保護と手軽なチャットAI活用法について紹介します。
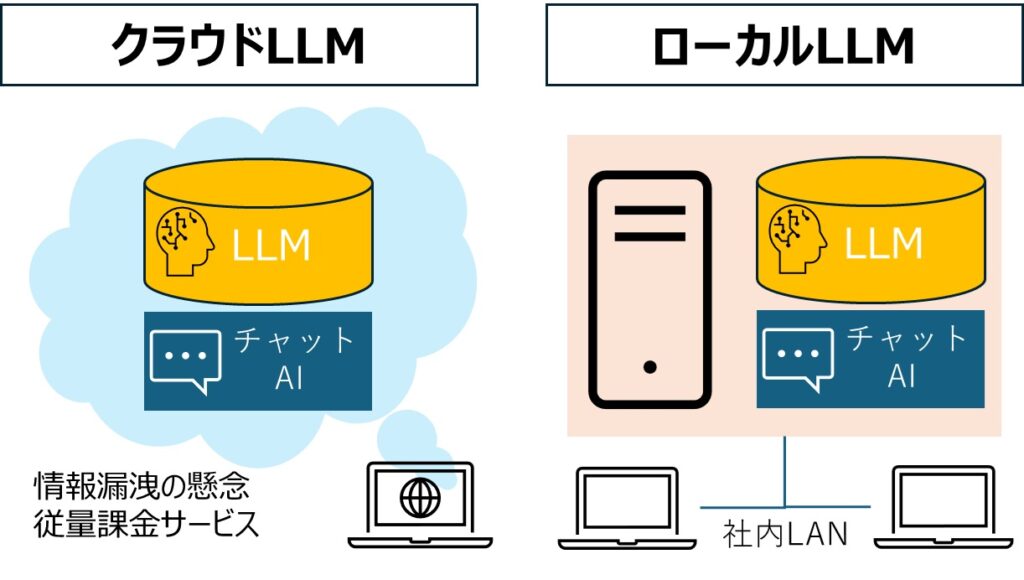
ローカルLLMの技術とは?
ローカルLLMは、デバイス内にLLMを保存し、クラウドを介さずに直接チャットAIを動作させる技術です。ローカルLLMを活用することで従量課金の回避や情報漏洩・プライバシーの懸念を軽減できます。
性能面では最先端のクラウド型チャットAIに劣るものの、十分実用的なレベルに達しています。

ローカルLLMの簡単導入と動作環境のポイント

ローカルLLMの導入は、専門的な知識がなくても可能です。
たとえば、「Jan」「Ollama」「LM Studio」などのソフトウェアを利用すれば、簡単にローカルLLMを導入できます。ただし、快適に動作させるためにはNVIDIAのGPUを搭載し、十分なVRAMを持つパソコンが望ましいでしょう。一方、GPU非搭載のパソコンでも、一定の性能があれば動作可能です。
VRAM
VRAM(ビデオランダムアクセスメモリ)とは、コンピュータやスマートフォンのグラフィック処理専用のメモリのことです。
主に画像や動画をスムーズに表示したり、ゲームや3Dアプリケーション、AIモデルを処理する際に使われます。
プログラミングで広がるローカルLLMの可能性

1. PythonライブラリでWebチャットAIを簡単作成
「Chainlit」や「Streamlit」は、PythonでWebインターフェースを構築するためのライブラリです。これらを使うことで、プログラミング初心者でも簡単にChatGPT風のチャットAIを作成できます。
- Chainlit
ローカルLLMを利用したチャットアプリケーションに特化したライブラリ。簡潔なコードで、会話型のAIを迅速に実装できるのが特徴です。 - Streamlit
データ可視化やインタラクティブなWebアプリを作成するためのライブラリ。AIモデルのデモサイトやカスタムツールの作成に最適で、わずかなコードで使いやすいWeb UIを提供します。
2. 高度なAIシステムを構築するライブラリ
「Transformers」や「LangChain」を使うと、より複雑で高度なチャットAIシステムを構築できます。
- Transformers
Hugging Faceが提供するライブラリで、数多くのLLMがサポートされています。大規模なモデルの読み込みや微調整を行うための標準的なツールです。 - LangChain
プロンプト設計やモデル間のチェーンを組むことで、複数のAIモデルを効果的に連携させられるライブラリ。チャットAIの文脈理解や情報検索に優れた性能を発揮します。

3. カスタマイズ可能な手法:RAGとファインチューニング
ローカルLLMをカスタマイズするには、「RAG」や「ファインチューニング」といった技術を活用します。
- RAG(Retrieval Augmented Generation)
AIが回答する際、外部の情報を検索して生成結果を強化する技術。たとえば、会社のFAQデータを検索しながら回答を生成するチャットボットに適しています。 - ファインチューニング
既存のLLMを特定のタスクに合わせて再訓練する方法です。企業独自のデータや特定の専門分野に対応したAIを構築できます。
スマートフォン時代を迎えるローカルLLMの進化

1. 小型LLMの台頭でスマートフォンがAI端末に進化
ローカルLLMの進化は、スマートフォン市場にも広がりを見せています。
「OpenELM」や「Phi-3-mini」といった小型LLMが登場し、スマートフォンの性能に適した軽量で効率的なAIモデルが開発されています。
これらの小型LLMは、AIの処理をクラウドに頼らず、端末上で高速かつプライバシーを保ちながら実現可能になっています。
- OpenELM
省電力かつ高効率の動作を実現するLLMで、スマートフォン向けのアプリやデバイス統合に特化。特定のタスクに最適化され、エッジデバイス上でのAI処理をサポートします。 - Phi-3-mini
スマートフォンやIoTデバイスでの動作を前提に開発された小型LLM。特に、音声アシスタントやリアルタイム翻訳といったアプリケーションに適しています。
2. Appleの「Apple Intelligence」に見る未来像
2024年にAppleが発表した「Apple Intelligence」は、同社のデバイスにおけるAIの新しい基盤となることが期待されています。
このローカルLLMは、iPhoneやMacに統合され、ユーザー体験を大幅に向上させる技術として注目されています。
特徴と強み
Apple製品の特徴であるセキュリティやプライバシー保護と完全に統合。端末上でAIを動作させることで、クラウドを介さない安全な処理が可能です。
また、Apple独自の最適化により、バッテリー消費や性能への影響が最小限に抑えられるよう設計されています。
今後の展望
「Apple Intelligence」は、iOSやmacOSのネイティブ機能として、メッセージの生成、画像の自動補正、アプリの操作支援など、多岐にわたる分野で活用される見込みです。
他のスマートフォンメーカーもこれに追随し、ローカルLLMがスマートフォン業界の標準となる可能性があります。
日本語特化型LLMとモデル選択のポイント

日本国内でも、ELYZA-japanese-Llama-2やFugaku-LLMなど、日本語に特化したLLMが企業から公開されています。これらのモデルは、日本語の自然な理解と生成に優れており、国内での利用に適しています。
ローカルLLMのファイルは、さまざまなバリエーションが存在し、選択時には以下の3つのポイントが重要です。
- ファイル形式: 多くの場合、「gguf形式」が使用されるため、拡張子が「.gguf」のファイルを選びます。
- パラメータ数: LLMの性能を左右する要素で、パラメータ数が多いほど性能は向上しますが、ファイルサイズも大きくなり、高性能なパソコンが必要となります。
- 量子化のビット数: パラメータの値を圧縮する際のビット数で、ビット数が小さいほどファイルサイズは小さくなり、低性能のパソコンでも動作可能ですが、LLMの性能は低下します。
これらの情報は多くの場合、ファイル名に含まれています。
たとえば、「ELYZA-japanese-Llama-2-7b-q4_0.gguf」というファイル名であれば、「ELYZA-japanese-Llama-2」がモデル名、「7b」がパラメータ数(70億)、「q4_0」が量子化のビット数を示しています。
LLMモデルの量子化のビット数の特徴
| ビット数 | 形式 | 特徴 | 利点 | 欠点 | 用途 |
|---|---|---|---|---|---|
| 32ビット | FP32(単精度) | 元のモデルの完全な精度を保つデフォルト形式。 | – 高精度 – 再現性が高い | – メモリ消費大 – 計算コストが高い | トレーニングや高精度が必要な場面 |
| 16ビット | FP16/BF16(半精度) | 半精度浮動小数点形式。トレーニングや推論に広く使用される。 | – 精度低下がほぼない – メモリ使用量がFP32の約半分 | – ハードウェア依存がある場合がある | トレーニングやリアルタイム推論 |
| 8ビット | INT8/FP8 | 整数型(INT8)や低精度浮動小数点型(FP8)。 | – メモリ効率が良い – 推論速度が向上 | – 精度がやや低下する可能性がある | 推論タスク、リソース制約のある場面 |
| 4ビット | INT4 | さらなる精度削減でリソース効率を追求。 | – メモリ使用量をさらに削減 – 小型デバイス向けに最適化 | – 精度低下が大きい場合がある | リソース制約が厳しい推論タスク |
おすすめの選択
- トレーニング時: FP16/BF16を推奨(FP32とほぼ同等の精度でメモリ効率が高い)。
- 推論時:
- 高精度が必要: FP16またはINT8。
- リソース制約が厳しい: INT8やINT4を検討。
- モデルの圧縮を重視: INT4や1ビット量子化。
用途とリソースに応じて選択してください!
まとめ:ローカルLLMの未来とその重要性

この記事ではローカルLLMについて取りあげました。ローカルLLMは、プライバシー保護やコスト削減の観点から、今後ますます重要な技術となるでしょう。技術の進化とともに、より多くのデバイスでの利用が期待されます。

