

オープンソースLLMは急速に進化しており、単純なベンチマークの高さだけで選ぶ時代ではなくなりました。企業導入する際に重要なのは性能の高さそのものではなく、自社の業務、ライセンス条件、運用コストに合っているかどうかです。
結論から言えば、企業が現実的に導入しやすいのは gpt-oss、Qwen 3、Mistral Small 3.2 です。一方でDeepSeek-R1は推論特化、Llama 4は長文脈やマルチモーダルに強みがある反面、用途や運用条件を選びます。この記事では企業利用という視点から、注目すべき5つのオープンソースLLMを比較します。
※この記事は2026年6月現在の情報を参考に制作しています
企業がオープンソースLLMを選ぶための3つの判断軸

オープンソースLLMを比較する時、企業が見るべき軸は大きく3つです。
- 性能:汎用型なのか推論特化型なのか、長文脈やマルチモーダルに強いのかで向く業務は変わります。
- ライセンス:企業利用では商用利用の可否だけでなく、改変、再配布、再学習、SaaS提供時の扱いまで確認する必要があります。
- 運用コスト:API課金ではなく、GPU、VRAM、同時利用数、保守を含めたインフラ負荷が発生します。とくに大規模モデルは性能以上に運用コストが導入可否を左右します。
企業導入におすすめのオープンソースLLM5選

では、前述した3つの軸を前提におすすめのオープンソースLLMの各モデルを比較していきます。
① gpt-oss 120b 20b(OpenAI)

gpt-ossは、ChatGPTが使えない企業でも社内環境で運用しやすいオープンソースLLMです。Apache 2.0ライセンスで公開されており、商用利用しやすい点も強みです。大規模な120bと軽量な20bがあり、用途やGPU環境に応じて選べます。どちらもツール呼び出しや構造化出力に対応しており、業務システムに組み込みやすい設計です。
1.性能の方向性
gpt-oss-120bは、数学推論、一般知識、コード生成といった幅広い領域で安定した性能を示す汎用LLMとして完成度の高いモデルです。gpt-oss-20bも軽量モデルとしては性能が高く、文書要約や社内Q&Aなどの用途で十分に実用レベルにあります。以下のような企業にとくにおすすめです。
- 外部AIサービスの利用が制限されている企業
- 社外に出せないデータを扱う業務
- 社内向けAIアシスタントや業務支援ツール
とくにgpt-oss-20bは、検証用途やスモールスタートに適しています。
2.ライセンスと商用利用
Apache 2.0ライセンスで提供されており、商用利用、改変、再配布に制限はありません。オープンソースLLMの中でも、法務面の扱いやすさは非常に高い部類です。
3.GPU要件と運用負荷
gpt-oss-120bは大規模モデルであり、本番運用ではA100 80GBやH100クラスのGPUを複数枚用意する構成が現実的です。長文脈処理や同時接続を考慮すると相応のインフラ投資が必要になります。
一方、gpt-oss-20bは単一GPU環境でも動作可能で、RTX 6000 AdaやA100単枚構成でも検証・小規模運用が可能です。スモールスタートしやすい点は大きな利点です。

② Qwen 3(Alibaba Cloud)
Qwen 3は、高性能と実用性のバランスがよい企業向けのオープンソースLLMです。0.6Bから235Bまで幅広いサイズがあり、用途や運用環境に合わせて選びやすい点が強みです。とくに上位モデルはコード生成や数学推論に強く、思考モードを切り替えられるため、速度重視にも深い推論にも対応しやすい万能型モデルです。
1.性能の方向性
Qwen 3は推論、コード生成、一般的な文章生成まで幅広く高水準です。とくに複雑な指示や多段階の思考が必要なタスクで強みを発揮します。119言語で学習されており、多言語対応や翻訳用途でも安定した性能を示すため、以下のような企業にとくに向いているでしょう。
- 推論精度と応答速度の両立を求める企業
- コード生成や業務ロジック支援を重視する開発部門
- 多言語対応が必要な業務やプロダクト
2.ライセンスと商用利用
Qwen 3はApache 2.0ライセンスで提供されており、商用利用や改変、再配布に制限はありません。オープンソースLLMとしては非常に扱いやすく、法務面での不安が少ない点が評価されています。
3.GPU要件と運用負荷
Qwen 3はサイズ展開が広く、運用設計の自由度が高いモデル群です。235B級は大規模GPUクラスタが前提ですが、7B〜32BクラスならA100やL40Sなどの単枚・少数構成でも現実的に運用可能です。思考モードを用途に応じて切り替えられるため、推論負荷をコントロールしやすいのも特徴です。
③ DeepSeek-R1(DeepSeek)

DeepSeek-R1は、推論性能を重視する企業や研究用途に向く推論特化型のオープンソースLLMです。DeepSeek-V3をベースに推論能力を強化しており、段階的に考えながら結論を導く設計が特徴です。単なる汎用モデルではなく、数学や論理、検証系タスクで強みを発揮し、知識蒸留の元モデルとしても存在感があります。
1.性能の方向性
DeepSeek-R1の最大の強みは、数学的推論や論理問題における高い精度です。汎用的な文章生成よりも、正確な推論結果を出すことを重視する設計となっており、用途によって向き不向きがはっきり分かれるでしょう。ですから、DeepSeek-R1ですべての業務を賄うのではなく役割を限定して使う運用が現実的です。以下のような業務を扱う企業にとくにおすすめです。
- 数学、論理、評価系タスクを扱う業務
- 高精度な判断や検証をAIに任せたいケース
- 他モデルの推論性能を底上げする蒸留用途
2.ライセンスと商用利用
DeepSeek-R1はApache 2.0ライセンスで公開されており、商用利用や改変、再配布に制限はありません。推論特化モデルとしては、法務面の扱いやすさも大きな利点です。
3.要件と運用負荷
DeepSeek-R1は推論特化型であり、計算負荷は比較的高めです。フル性能を発揮させるには高性能GPUを複数枚用意する構成が望ましく、特に数学推論や長時間推論を行う場合はメモリ容量も重要になります。
④ Llama 4(Meta)
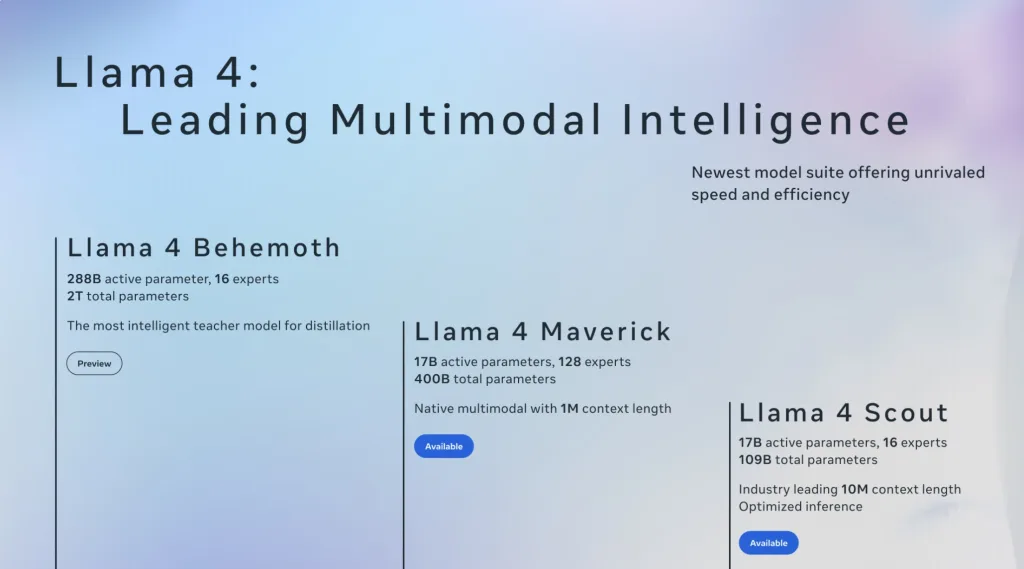
Llama 4は、長文脈処理や画像入力にも対応した高性能なオープンソースLLMです。MoE構造を採用し、ScoutとMaverickの2系統が用意されています。とくにMaverickは4000億級の大規模モデルで、性能面では最上位クラスですが、ライセンス条件には注意が必要です。
1.性能の方向性
Llama 4はとくに長文脈処理能力が特徴で、Scoutは数百万トークン級、Maverickも約100万トークンのコンテキストを扱えるとされています。文章生成、コード生成、画像理解まで幅広いタスクで高い性能を示すため、以下のような業務で使う企業におすすめです。
- 性能を最優先する大規模プロジェクト
- 長文脈やマルチモーダル処理が必須の業務
- ライセンス管理を前提に運用できる組織
2.ライセンスと商用利用
Llama 4はMeta独自のCommunity Licenseで提供されます。商用利用自体は可能ですが、月間アクティブユーザー数が一定規模を超えるサービスでは、追加の許諾が必要になります。
また、モデル出力を他モデルの学習に利用することが禁止されている点も、企業利用では重要な注意点です。性能が高い分、ライセンス条件を正確に理解した上での利用が不可欠です。
3.要件と運用負荷
Llama 4は400B級の大規模構成を含み、本格運用にはH100クラスのGPUを複数台用意する必要があります。高帯域メモリと安定したクラスタ環境が前提なため、小規模オンプレ環境での運用は難易度が高いので、研究用途や大規模プロジェクト向けと考えるのが現実的です。性能は高いものの、インフラコストとのバランス判断が不可欠です。
⑤ Mistral Small 3.2(Mistral AI)
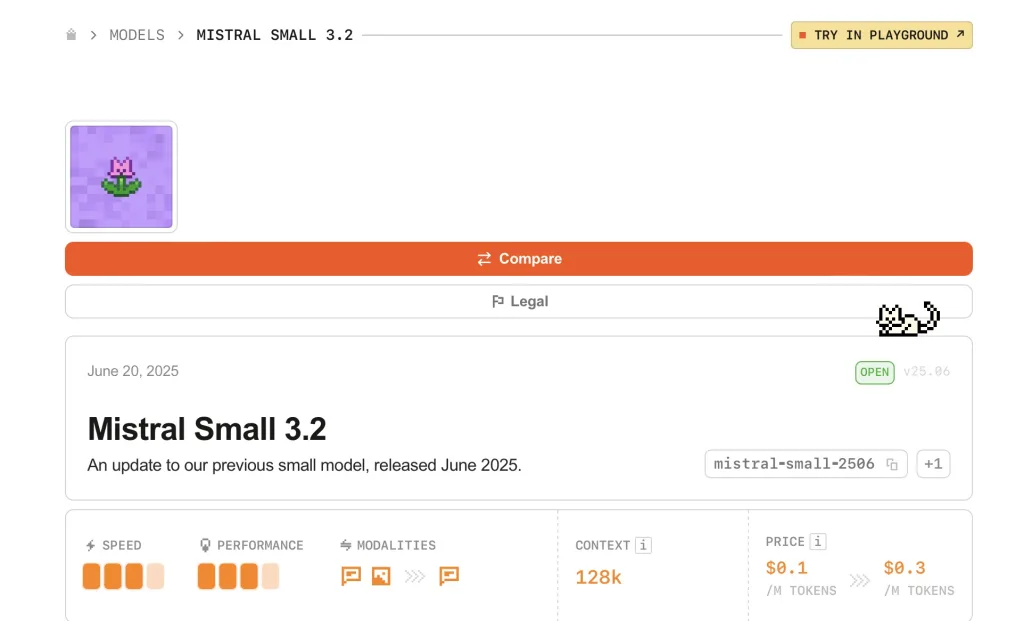
Mistral Small 3.2は、性能と運用コストのバランスがよい実務向けのオープンソースLLMです。24B級の中型モデルで、長文脈処理や画像入力にも対応しており、業務で扱いやすいサイズ感が強みです。指示追従性や安定性も高く、関数呼び出しにも対応しているため、社内アシスタントやRAG用途など、現場で回しやすいモデルです。
1.性能の方向性
Mistral Small 3.2は、汎用的な文章生成や要約に加え、コード生成でも高い水準を狙えるモデルです。超大規模モデルのような圧倒的推論力ではなく、日常業務に必要な品質を安定して出す方向性に強みがあります。
- 社内文書の要約、検索、FAQなどを安定運用したい企業
- RAG型の社内アシスタントを作りたい組織
- 大規模GPU環境がなく、現実的なコストで始めたいケース
2.ライセンスと商用利用
Apache 2.0ライセンスで公開されており、商用利用、改変、再配布に制限はありません。法務面の扱いやすさという点でも、企業が採用しやすいモデルです。
3.GPU要件と運用負荷
Mistral Small 3.2は24B級で、企業がオンプレミス環境で運用しやすいサイズ感です。A100 80GBやRTX 6000 Adaクラスでの単枚〜少数構成でも十分な実用性能を発揮します。巨大モデルほどのインフラ投資を必要としないので、現実的なコストで本番展開できる点が評価ポイントになります。
おすすめのオープンソースLLM5つをわかりやすく比較
| モデル | 強み | 注意点 | ライセンス | 商用利用 | こんな企業におすすめ |
|---|---|---|---|---|---|
| gpt-oss 120b 20b | 汎用力が高く社内AIの基準になりやすい | 120bは計算資源が必要 | Apache 2.0 | 可 | まず失敗しない土台が欲しい企業 |
| Qwen 3 | 推論の深さと速度を使い分けやすい万能型 | 提供形態や運用ポリシーは事前確認が必要 | Apache 2.0 | 可 | 部署ごとに使い分けたい企業 |
| DeepSeek-R1 | 推論特化で数学や検証系に強い | 汎用チャット用途では過剰になりやすい | Apache 2.0 | 可 | 推論精度が最優先の企業 |
| Llama 4 | 高性能、長文脈や画像対応も視野に入る | ライセンス制約とインフラ負荷が重い | Community License | 条件付き | ライセンス管理が出来る企業 |
| Mistral Small 3.2 | 実務で回しやすいサイズ感と安定性 | 最上位の推論力を求める用途には不向き | Apache 2.0 | 可 | 現実的なコストで定着させたい企業 |
モデル別 年間概算インフラ費
また、多くのIT担当者がもっとも気になるであろう構成とコストに関しては、別途でまとめました。
| モデル | 想定構成 | 年間概算コスト | 想定用途規模 |
|---|---|---|---|
| gpt-oss-120b | H100 × 8 | 約2,000万〜3,000万円 | 全社基盤レベル |
| gpt-oss-20b | A100 × 1〜2 | 約400万〜800万円 | 部門利用 |
| Qwen 3(32B級) | A100 × 2 | 約800万〜1,200万円 | 複数部署利用 |
| DeepSeek-R1 | H100 × 4〜8 | 約1,500万〜3,000万円 | 推論特化基盤 |
| Llama 4(400B級) | H100 × 8〜16 | 3,000万〜6,000万円超 | 大規模プロジェクト |
| Mistral Small 3.2 | A100 × 1 | 約300万〜600万円 | 社内RAG・FAQ |
年間概算コストを算出する際の前提条件は以下のとおりです。参考にしてください。
- GPUサーバーは3年償却
- 24時間稼働想定
- 電力・保守含む概算
- 同時利用数は中規模企業想定
まとめ:2026年のオープンソースLLM選定で重要なこと

2026年を見据えたオープンソースLLM選定では、単純な性能比較ではなくどのモデルをどの業務に使うかという整理が重要になります。すべての企業にとって最適な万能モデルは存在しません。企業導入する際には、以下の視点を意識すると良いでしょう。
- 社外にデータを出さずに運用できること
- 商用利用や将来運用に不安のないライセンスであること
- 自社のインフラや体制で無理なく回せること
本記事の比較を参考に、2026年以降も継続して使える生成AI基盤を検討してください。

