

Efficient GRPOが変える大規模モデルの常識
「長い文脈を扱いたいけれど、GPUメモリが足りない……」そんな悩みを抱えていませんか?
本記事では、Unslothが提案する「Efficient GRPO」アルゴリズムによって、従来では不可能に近かった長大なコンテキスト長の学習を、圧倒的に少ないVRAMで実現する最新手法を解説します。
理論と実装を両面から紹介し、意外に知られていない実装上の落とし穴や、VRAM消費量が10分の1以下になった実績など、開発者なら「なるほど!」と思わず唸るポイントが満載。読むだけで最新トレンドを把握し、自分のプロジェクトに応用するヒントを得られます。
長いコンテキストを支える「Unsloth Efficient GRPO」
現在、GRPO(Generative Reinforcement with Policy Optimization)の大きな課題のひとつとして「長いコンテキストを扱う際のメモリ消費」が挙げられます。Unslothが新たに開発した「Efficient GRPO」アルゴリズムは、これまで標準実装と比較して10倍もの長い文脈を90%も少ないVRAMで扱えるようにした革命的な手法です。
従来手法では驚きのVRAM消費
たとえば、TRLやFlash Attention 2(FA2)を使った標準的なGRPO実装で、Llama 3.1(8B)をコンテキスト長20Kで動かそうとすると、実に510.8GBものVRAMが必要になることもあります。しかし、Unslothのアルゴリズムを用いれば、わずか54.3GBまで削減が可能。これは「そんなに減るの?」と疑ってしまうほどの差です。
省メモリを実現する3つの工夫
- 新しいメモリ効率化線形アルゴリズム
GRPOの損失計算における不要なテンソルを極限まで削減し、8倍以上ものVRAM削減を実現しながら、処理速度面でもtorch.compileなどを駆使して高速化。 - Unsloth独自の勾配チェックポイント
中間アクティベーションをシステムRAMへ賢くオフロードし、わずか1%の性能低下で数百GB単位のVRAMを節約。生成回数が多い(num_generations=8など)ケースほど効果が大きくなります。 - vLLMとのメモリ空間統合
推論エンジン(vLLM)が使うメモリ領域を一体化し、余分な16GBの消費をカット。さらにFP8のKVキャッシュを利用することで、キャッシュ領域を2倍圧縮するオプションも利用可能です。
数字で見るUnslothの強み
たとえば、20Kのコンテキスト長に対して標準実装ではGRPO部分だけで78.3GBものVRAMを消費するのに対し、Unsloth方式なら9.8GBで済みます。これまで長い文脈でのGRPOは“メモリの壁”に阻まれがちでしたが、この手法によりハードルが格段に低くなりました。
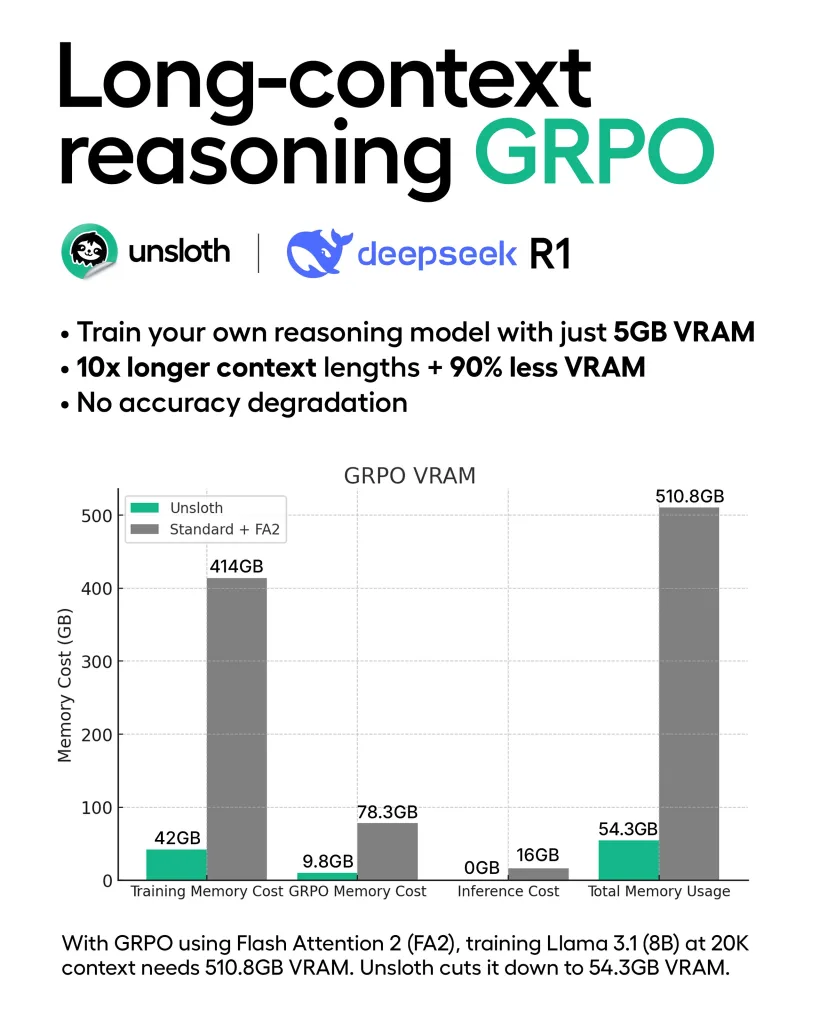
上の図は、GRPOの実行に必要なVRAM使用量を「標準的なFlash Attention 2(FA2)を使った場合」と「Unslothを使った場合」で比較したグラフです。横軸に「トレーニングメモリコスト」「GRPOメモリコスト」「推論コスト」「合計メモリ使用量」という4つの項目があり、それぞれについてUnslothが大幅にメモリを節約している様子が一目で分かるようになっています。
具体的には、Llama 3.1(8B)モデルをコンテキスト長20Kで扱う際、標準手法では合計で510.8GBものVRAMを必要とするところ、Unslothの手法を使うと約54.3GBにまで削減できる、という点を強調しています。長い文脈(Long-context)推論を実現しながら大幅にVRAMを節約できるのです。
GRPO実装での意外な“落とし穴”と回避策
Efficient GRPOの技術的背景には、実装時のさまざまな検討があります。たとえば、DeepSeekの論文で初出のGRPOが採用する「逆KLダイバージェンス」との兼ね合いや、detach() の扱い方に関する議論など、実装を追うなかで驚きの発見もありました。
- 逆KLダイバージェンスの正しい導入
従来から「GRPOの実装で逆KLをどう計算するか」という話題はよく取り上げられます。特に自動微分の扱いでdetach()を外すと学習が破綻するなど、注意が必要な部分です。 - 線形クロスエントロピー手法の工夫
Horace Heによる線形クロスエントロピー実装を参考にしつつ、float16・float8の混合精度下でのスケーリング問題もクリア。最適化や安定性を確保しています。
vLLMとの連携でさらに高速&省メモリ
Unslothは標準でvLLMを統合。
fast_inference=Trueやfloat8_kv_cache=Trueを設定するだけで、推論を高速化しながらKVキャッシュを半分に圧縮。- ユーザーがvLLMのSamplingParamsを柔軟に設定して、
min_pやtemperatureなどを微調整できるため、生成の多様性を損なわずに高効率化を図れます。
その他のアップデート情報
- 動的4bit量子化
Unslothの動的量子化(Dynamic 4-bit)をvLLMでも直接活用可能に。これにより、精度の低下を最小限に抑えつつ、さらにVRAM節約を実現しています。 - Perplexity AIのR1-1776にも対応
DeepSeek-R1をベースに再学習されたPerplexityのR1-1776モデルがDynamic GGUF形式でも配布され、ローカル環境での検証が容易になりました。 - GitHub Universe 2024でのインタビュー公開
Unsloth開発者のDaniel & Michael兄弟が、オーストラリアでのバックグラウンドから本プロジェクトの立ち上げ、コミュニティとの交流まで詳しく語っています。YouTubeで視聴可能。
まとめ
長いコンテキストを扱う言語モデルを開発するにあたり、巨大なVRAM消費は多くの研究者・エンジニアにとって長年の頭痛のタネでした。しかし、UnslothのEfficient GRPOアルゴリズムを使えば、ほぼ10分の1という圧倒的なメモリ削減を実現可能です。これからの大規模言語モデル開発では、長文テキストを簡単に処理できるだけでなく、ハードウェアコストを大幅に下げることが期待されます。興味を持たれた方は、ぜひ公式ドキュメントや公開ノートブックをチェックしてみてください。
