

Qwen3:次世代AI言語モデルがもたらす新たな可能性
アリババが新たに公開したQwen3モデルは、OpenAIやGoogleの最新モデルに匹敵する性能を誇るオープンソースのAI言語モデルです。意外な事実としては、Qwen3は2350億パラメータの巨大モデルでありながら、GPUメモリの使用量を大幅に削減している点が挙げられます。
この記事では、Qwen3がどのような技術革新をもたらし、企業や研究者にとってどのようなメリットがあるのかを紹介し、Qwen3の多言語対応や異なる用途に応じた柔軟な利用方法についても詳しく解説します。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
オープンソースLLMのQwen3とは?
Qwen3シリーズは、Alibabaが開発した最新の大規模言語モデル(LLM)ファミリーで、2つの「エキスパートの混合(MoE)」モデルと6つのデンス(Dense)モデル、合計8つのモデルで構成されています。以下に、それぞれのモデルの詳細を表にまとめました。
Qwen3 モデル一覧
| モデル名 | タイプ | 総パラメータ数 | アクティブパラメータ数 | 層数 | ヘッド数(Q/KV) | エキスパート数(総数/アクティブ) | コンテキスト長 |
|---|---|---|---|---|---|---|---|
| Qwen3-0.6B | Dense | 6億 | 6億 | 28 | 16 / 8 | – | 32K |
| Qwen3-1.7B | Dense | 17億 | 17億 | 28 | 16 / 8 | – | 32K |
| Qwen3-4B | Dense | 40億 | 36億 | 36 | 32 / 8 | – | 32K |
| Qwen3-8B | Dense | 80億 | 80億 | 36 | 32 / 8 | – | 128K |
| Qwen3-14B | Dense | 140億 | 140億 | 40 | 40 / 8 | – | 128K |
| Qwen3-32B | Dense | 320億 | 320億 | 64 | 64 / 8 | – | 128K |
| Qwen3-30B-A3B | MoE | 320億 | 30億 | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | MoE | 2350億 | 220億 | 94 | 64 / 4 | 128 / 8 | 128K |
それぞれのモデルの特徴
- 「Dense」モデルは、すべてのパラメータを使用して推論を行うモデルです。
- 「MoE(Mixture of Experts)」モデルは、複数のエキスパート(専門家)ネットワークから一部を選択して使用することで、計算効率を向上させたモデルです。
- 「アクティブパラメータ数」は、推論時に実際に使用されるパラメータの数を示します。
- 「コンテキスト長」は、モデルが一度に処理できるトークン数を示します。
Qwen3の特徴:ハイブリッドリーズニング&ダイナミックリーズニングの実現

Qwen3モデルは「ハイブリッドリーズニング」または「ダイナミックリーズニング」機能を提供するように訓練されています。ユーザーは高速で正確な応答と、より時間と計算リソースを消費するリーズニングステップを切り替えることができます。
これは科学、数学、エンジニアリングなどの専門分野での複雑なクエリに対応するためのアプローチです。Nous Researchや他のAIスタートアップ、研究集団が開発した手法を採用しています。
複雑なタスクには「Thinking Mode」

Qwen3では、Qwen Chatウェブサイトの「Thinking Mode」ボタンを使用するか、ローカル展開やAPI経由でモデルを使用する際に/thinkや/no_thinkなどの特定のプロンプトを埋め込むことで、タスクの複雑さに応じて柔軟に使用できます。
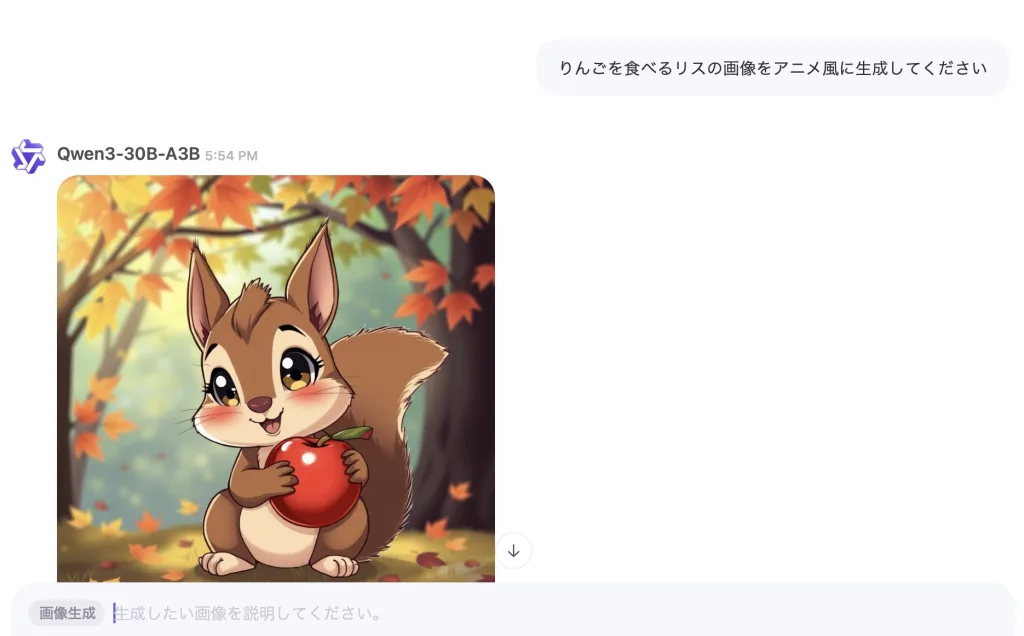
Qwen Chatウェブサイトの初期使用では、画像生成が比較的迅速に行われ、プロンプトへの準拠性も高く、とくに画像にテキストを組み込む際のスタイルマッチングが優れていました。
ただし、中国のコンテンツ制限(天安門広場の抗議活動に関するプロンプトや応答の禁止など)が適用される点に注意が必要です。
モデルの多様性と多言語対応
Qwen3は、MoEモデルとデンドモデルの両方を提供しており、ユーザーは異なる規模とアーキテクチャのモデルから選択できます。
これにより、多様なニーズや計算リソースに合わせた利用が可能になります。Qwen3は119の言語と方言をカバーしており、主要な言語群を網羅しています。これにより、グローバルな研究や展開が容易になり、多様な言語環境での利用が可能になります。
前モデルQwen2.5から大幅に進化したQwen3

Qwen3の訓練は、前モデルQwen2.5から大幅に進化しています。事前学習データセットの規模は2倍になり、約36兆トークンに達しています。データソースにはウェブクロール、PDFのようなドキュメント抽出、および数学やコーディングに特化した前のQwenモデルによって生成された合成コンテンツが含まれています。
訓練パイプラインは、3段階の事前学習プロセスと4段階の事後学習リファインメントから構成されており、ハイブリッド思考と非思考機能を実現しています。これらの訓練の改善により、Qwen3のデンドベースモデルは、はるかに大きなQwen2.5モデルと同等かそれ以上の性能を達成しています。
配置オプションの多様性
Qwen3モデルの配置オプションは非常に多様です。ユーザーはSGLangやvLLMなどのフレームワークを使用して、OpenAI互換のエンドポイントに統合できます。ローカル使用には、Ollama、LMStudio、MLX、llama.cpp、KTransformersなどのオプションが推奨されています。
また、モデルのエージェント機能に興味があるユーザーは、Qwen-Agentツールキットを活用することで、ツール呼び出し操作を簡素化できます。
企業意思決定者がQwen3モデルを活用する意味
エンジニアリングチームは、既存のOpenAI互換エンドポイントを新しいモデルに数時間で切り替えることができます。MoEチェックポイント(2350億パラメータのうち220億が活性化、300億のうち30億が活性化)は、約20〜300億のデンドモデルのGPUメモリコストでGPT-4クラスのリーズニングを提供します。
公式のLoRAとQLoRAフックにより、プロプライエタリデータを第三者ベンダーに送信せずにプライベートファインチューニングが可能です。デンドバリアント(0.6Bから32B)は、ラップトップでのプロトタイピングからマルチGPUクラスターへのスケーリングまで、プロンプトの書き換えなしで簡単に使用できます。
Qwen3:まとめ

Qwenチームは、Qwen3を単なる改良ではなく、人工一般知能(AGI)や人工超知能(ASI)への重要な一歩として位置付けています。次期フェーズの計画には、データとモデルサイズのさらなるスケーリング、コンテキスト長の延長、モダリティサポートの拡大、環境フィードバックメカニズムを用いた強化学習の強化が含まれています。
大規模AI研究のランドスケープが進化し続ける中、Qwen3のオープンウェイトリリースは、研究者、開発者、組織が最先端のLLMで革新を遂げるための障壁を低める重要なマイルストーンとなっています。

