

最新のAI技術には興味があるけれど、「難しそう」「結局どんな役に立つの?」と感じてしまう方も多いのではないでしょうか。実は、近年注目を集める“マルチモーダル”分野は、画像や動画はもちろん、文書構造の解析や長時間の映像の要点抽出など、想像以上に幅広いことができるのです。
本記事で取り上げる「Qwen2.5-VL」は、そうした多様なデータを一度に理解し、実際にパソコンやスマートフォンの操作まで行える画期的なモデルです。
Qwen2.5-VLとは何か
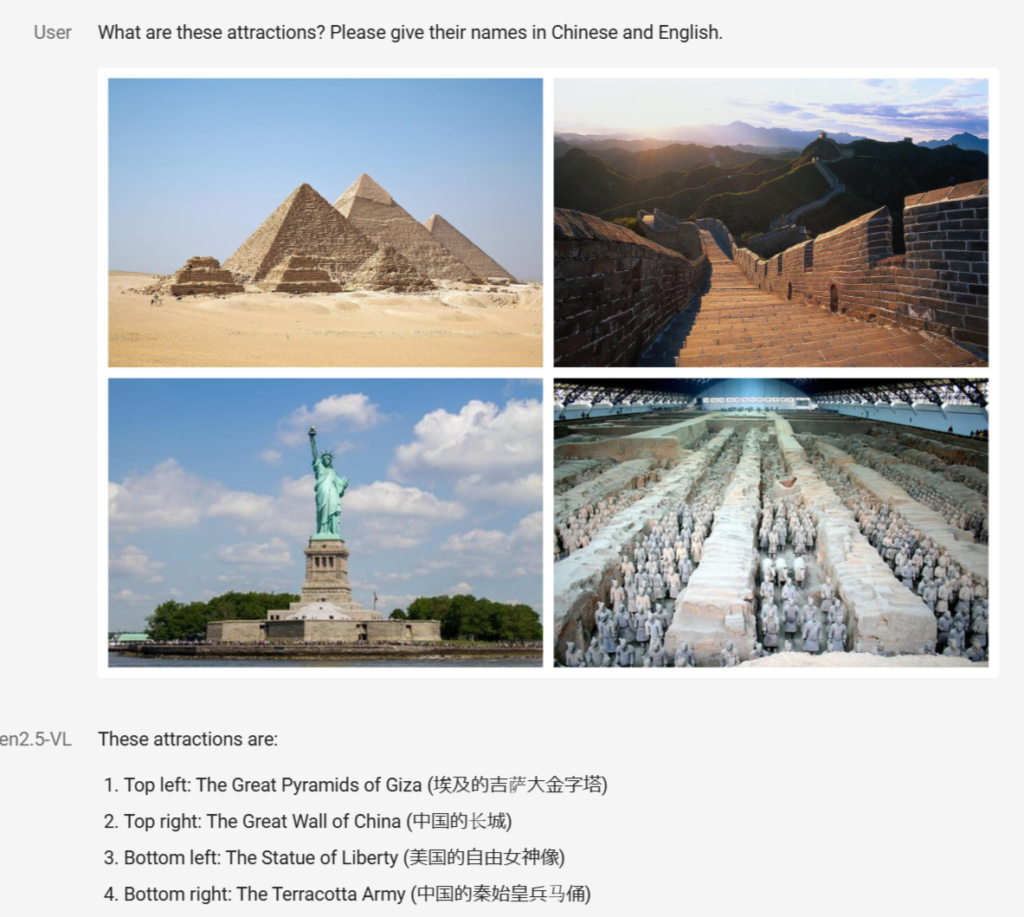
2025年1月26日、アリババクラウドは最新の視覚と言語を統合した大規模言語モデル(LLM)である「Qwen 2.5 VL」を公開しました。
「Qwen2.5-VL」は、Qwenシリーズの最新フラッグシップ・ビジョン&ランゲージモデルです。先行モデル「Qwen2-VL」の強みをさらに発展させ、画像・動画内の物体やテキストを精緻に認識するだけでなく、レイアウトやチャート、さらには長時間の動画を“時間軸”ごとに理解し、指定されたイベントのみを抜き出せるなど、総合的なマルチモーダル認識能力を備えています。
このモデルは以下のようなタスクに対応できます。
- 画像内のさまざまな要素を理解・分析
一般的なモノや動物を認識するだけでなく、レイアウトやアイコン、グラフといったビジュアル要素を総合的に判断します。 - エージェントとして自律的にツールを操作
ユーザの依頼に応じて、PCやスマートフォン上でのアプリ操作などを行い、タスクの完了をサポートします。 - 1時間以上の動画コンテンツを理解
絶対時間を考慮しながら、特定のイベントがどの時点で発生したかを pinpoint し、その内容を抽出可能です。 - 物体の正確な位置情報を返す
バウンディングボックスやポイントの形式で、標準化されたJSON出力を行い、オブジェクトを正確にローカライズします。 - 帳票や文書の構造化出力
領収書や伝票、複雑なレイアウトの書類を読み取り、構造化データとして抽出してくれます。
これらの機能は、ビジネスでの自動処理や検索、教育、さらにはクリエイティブな分野など、多様な現場での活躍を期待させます。
Qwen 2.5 VLの主要な特徴

1. ビジュアル認識の大幅強化
従来より多くのデータセットを活用することで、花や動物、観光名所はもちろん、映画やテレビに関連するキャラクターやブランド商品など、幅広い対象を高精度で認識可能になりました。さらに、文書に描かれた図表やレイアウトも詳細に理解できます。
2. 高度なローカライズ技術
画像内のオブジェクトを囲むバウンディングボックスや点群を返し、そのデータを統一フォーマットのJSONで提供。位置座標の正確さにこだわることで、視覚的な推論やリアルタイムな検出に役立ちます。
3. 強化されたOCRと情報抽出
縦書きや多言語、多方向のテキストでも認識が精細化。書類や看板など、複数のレイアウト要素が混在する画像でも重要なテキスト情報を抽出し、処理することができます。金融業務や商用領域などでの書類自動化がさらに進むでしょう。

4. ユニークな文書解析フォーマット「QwenVL HTML」
独自の<html>形式により、見出しや段落、画像の挿入位置などを保持したまま文書構造を再現。研究論文からWebページ、雑誌レイアウトまで、多様なドキュメントを一貫した形式で扱えます。
5. 超長尺動画の理解
1時間を超える長尺動画に対して、動的なFPS(フレームレート)で学習し、絶対時間を識別可能。複数のイベントが起こるタイミングを正確に捉え、ユーザの質問に沿って該当箇所を抜き出すことができるため、映像編集や要約に強みを発揮します。
6. PCやスマホの操作代行(Visual Agent機能)
マルチモーダルを活かした推論により、OSやアプリを操作。フライト予約やSNS投稿など、対話形式の指示に応じてタスクを実行します。これは単なるチャットボットを超えた「エージェント」としての次世代的役割を期待させます。

パフォーマンスとモデルサイズ
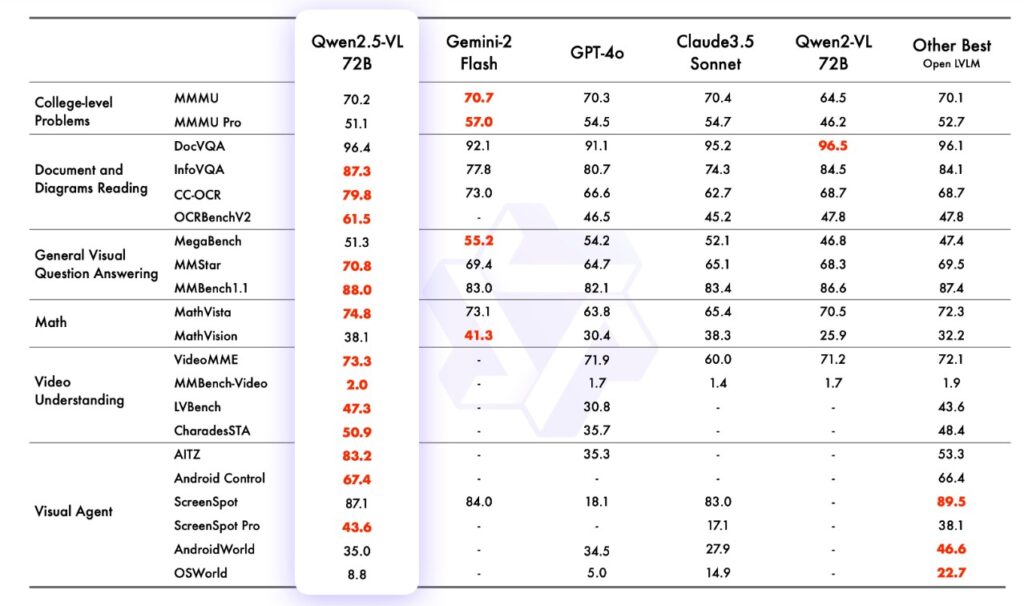
「Qwen2.5-VL-72B-Instruct」などのフラッグシップモデルは、複数のベンチマークにおいて最先端(SOTA)水準の成績を収めています。さらに7Bや3Bといった小規模版も公開されており、端末側(エッジAI)での処理や高速動作が必要なシーンでも、それぞれのニーズに合わせて導入できます。
大規模データセットによる事前学習と、綿密な指示調整(Instructチューニング)によって、人間の指示に対する的確な応答や専門的内容への対応が大幅に強化されています。とくに文書理解やチャート解析など、従来のモデルが苦手とする分野においても優れた性能を示します。
モデルの更新点

時間と空間の同時学習
動画解析のために動的FPSや絶対時間エンコーディングを導入。画像の解像度を保持する工夫も行い、細部までの認識力が向上しています。
ビジュアルエンコーダの効率化
ViT(Vision Transformer)をベースに、フルアテンション層とウィンドウアテンション層を組み合わせることで、学習時や推論時の計算負荷を抑えつつ高精度を実現しています。アーキテクチャをLLM側と統一化し、全体の動作効率を高めました。
Qwen2.5 VLにはどのようなメリットがあるのか

- ビジネス面:
- 書類処理の自動化、動画会議や監視映像の自動要約、商品データベース管理などの幅広い自動化や効率化が期待できます。
- 教育・研究分野:
- 大量の論文や学術資料を効率的に解析し、重要事項のみを抽出・要約。さらに動画や画像の内容を自動で解析・分類することで、学習コンテンツの改善にも活用可能です。
- クリエイティブ領域:
- 映画やドラマの映像から特定のシーンだけを切り出すなど、映像編集を効率化し、新たな表現やアイデア創出にもつながります。
- ユーザ支援:
- 視覚に関連するタスクを総合的に行えるため、例えばスマートフォン操作の代行や写真整理、オンラインサービスの自動検索など、多岐にわたるサポートを可能にします。
Qwen2.5-VL:まとめと今後の展望

Qwen2.5-VLは、画像や動画、テキストをシームレスに理解・操作するマルチモーダル大規模モデルとして登場し、その応用範囲は非常に広範囲です。今後はさらなる推論能力の向上や新しいモダリティ(音声・3Dデータなど)の取り込みが予定されており、多彩な分野でイノベーションをもたらす可能性が高いでしょう。
「画像や動画を理解するAIは、本当にどこまでできるのか?」という疑問は、ここ数年で急速に答えが進化しています。Qwen2.5-VLの登場により、その答えはさらに明確で、しかも実用的なものへと変わりつつあります。この記事を機に、新時代のマルチモーダル技術がもたらす変革にぜひ目を向けてみてください。ビジネス、研究、日常のあらゆるシーンで、近い将来AIの活躍を目の当たりにするはずです。

