
あなたがもし「たった1枚の写真と音声データで、高品質な人間動画を自在に生成できる」と聞いたら信じられるでしょうか? 本記事では、そんな意外性と驚きに満ちた最新技術「OmniHuman」を分かりやすく解説します。
OmniHumanとは?
OmniHumanは、ByteDanceの研究チームによって開発されたワンステージ型の条件付きヒューマンアニメーションモデルです。
たった1枚の人間画像に音声や映像、あるいはその両方を組み合わせることで、非常に自然なモーションと質感を持つヒト動画を生成します。参考までに、こちらのアインシュタインの動画をご覧ください。
この動画は、OmniHumanによって作られたものです。わずかな入力情報(特に音声のみの場合など)からでも、驚くほどリアルな動きを再現できます。
特徴1:あらゆる画角・体型に対応
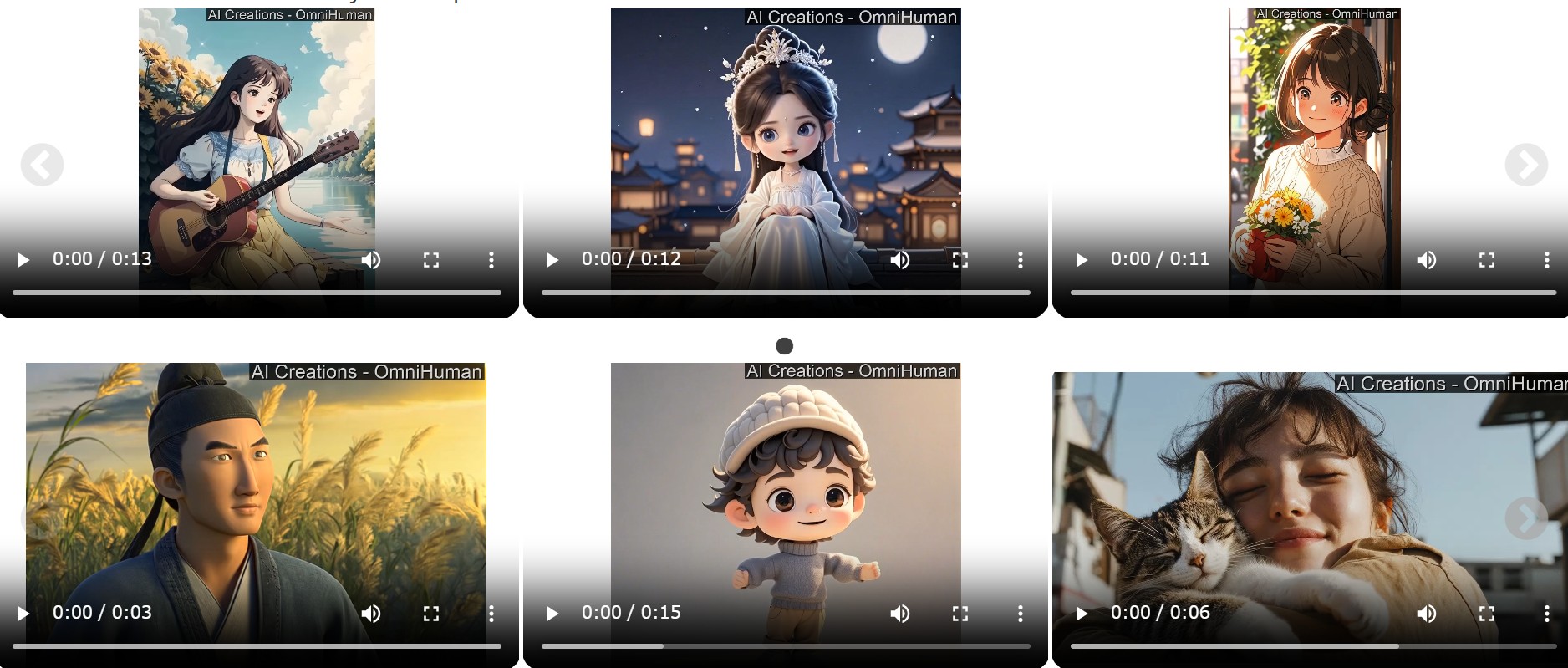
OmniHumanは、縦長・横長などのアスペクト比の違いや、全身・半身・バストアップといった多様な構図でも自然な結果を生み出します。照明や質感など、細部にわたってリアルさを再現するのが大きな強みです。
特徴2:音声と映像の両方に対応
入力が音声だけの場合でも、人間のジェスチャーや口パクをかなり精巧に再現できます。さらに、参考となる動画の動きをなぞる「ビデオドライビング」にも対応しており、複数のモーション要素を同時に制御可能です。
特徴3:多彩なスタイルとモーション表現
OmniHumanはリアルな人間だけではなく、イラストやアニメキャラクター、動物などの多彩な被写体にも適用できます。各スタイルの特徴的な動きやデザインをキープしながら自然なモーションを生成できる点がユニークです。
使用例と可能性
- 動画クリエイションの効率化:宣伝動画やプレゼン資料のキャラクターアニメーション作成が圧倒的にスピードアップ
- エンターテインメント:ゲームやバーチャルYouTuberなどでの新しい表現手法
- 教育・トレーニング:リモート授業や遠隔トレーニングにも応用可能
こうした広がりのあるアプリケーションは、映像制作やコミュニケーションのあり方を大きく変えるかもしれません。
著名な外国人の歌手に日本語の歌を歌ってもらうことも可能です。(Xの投稿を埋め込み)
5. ByteDance OmniHuman-1 AI example: pic.twitter.com/wuatqrey2G
— el.cine (@EHuanglu) February 22, 2025
OmniHumannに関する注意点・今後の展開
現在のところ、OmniHumanのサービスやダウンロードは一切提供されていません。インターネット上にある誤った情報やなりすましサイトには十分ご注意ください。
今後の進展については、公式からのアナウンスがあり次第、アップデートされる予定です。研究チームは、問い合わせや権利に関する懸念などにも迅速に対応しているとのことですので、興味のある方は注目しておくと良いでしょう。
OmniHuman:まとめ

OmniHumanの登場によって、「1枚の画像+音声」という最小限の条件から、本格的なヒト動画を生み出す未来がすぐそこまで来ています。
今後の研究開発が進めば、さらに品質が向上すると同時に、より広範な利用ケースが想定されるでしょう。映像表現のハードルが劇的に下がることで、新しいクリエイターやサービスが生まれる可能性も期待されます。

