

「最近話題の大規模言語モデルには興味があるけれど、どれも高価なGPUや巨大な計算資源を必要とするものばかり……」と感じていませんか? 実は、意外と少ない計算コストでも、高い性能を発揮できるモデルがあるのです。
本記事では、最新のオープンモデル「DeepSeek-V3」を切り口に、最先端の“MoE(Mixture of Experts)”技術や学習・推論の裏側に迫ります。読めば「大規模モデル=大規模リソース」という常識への疑問が解消され、未来のAIインフラに関するヒントを得られることでしょう。
フロンティアモデルとオープンモデルの現状
近年、巨大な予算と最先端のGPUを投入し、圧倒的な性能を持つ「フロンティアモデル」が次々と登場しています。一方で、オープンコミュニティ主導の開発や新興企業による「オープンモデル」も台頭しており、驚くほど高い性能を示す例が増えてきました。
昨年末に発表された「DeepSeek-V3」は、その代表格として注目を浴びています。実際、このモデルの登場直後には海外の大手IT企業(GAFAM)の株価が一時下落したほどです。これまで大手企業だけがリードしていた大規模言語モデル市場に、新たなプレーヤーが加わった象徴的な出来事といえるでしょう。
DeepSeekの技術的背景
DeepSeekは以前から大規模言語モデル(LLM)の研究で高い評価を得ており、数多くの論文を発表してきました。今回のDeepSeek-V3は、DeepSeek-V2やV2.5といった従来モデルの後継となる最新バージョンです。
このモデルの最大の特長は、「比較的低コストなGPUを使いながら、フロンティアモデルに迫る性能を実現する」という点にあります。DeepSeekではNVIDIAの「H800」というGPUを用いて学習を行っていますが、これは米中の輸出規制対策としてメモリバンド幅を抑えたH100の派生版であり、通常のH100より低性能とされています。それでも、2,048 GPUで約58日という学習期間で済み、たとえばLlama3-400Bの学習コスト(約16,000 GPUで3か月)と比べて1/10~1/20ほどの計算リソースで済むという試算が示されています。
MoE(Mixture of Experts)技術とは
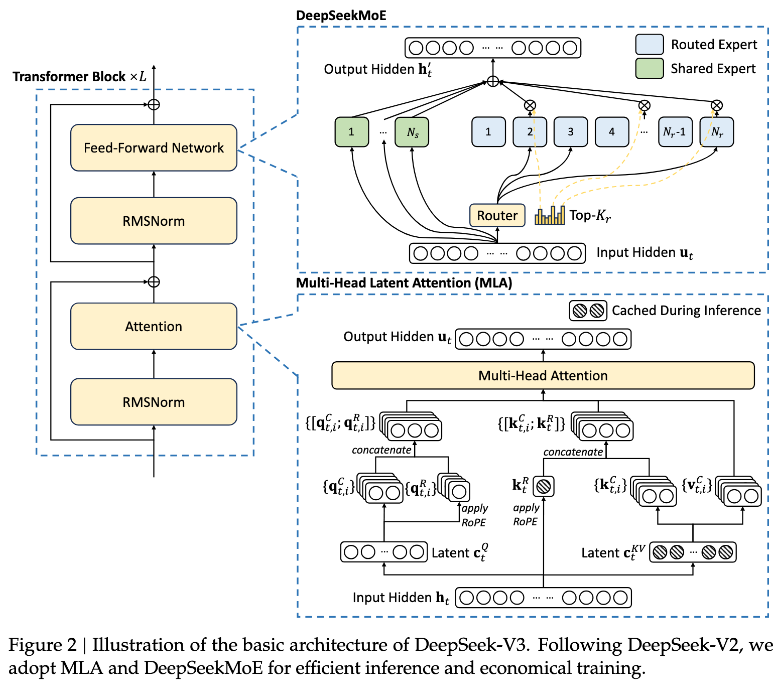
DeepSeek-V3の核となるのが、2018年頃から注目を集めてきた「MoE(Mixture of Experts)」という技術です。これは入力されるトークンごとに複数の“エキスパート”が存在し、どのエキスパートが処理を行うかをルーターが選択する仕組みを指します。
- 一部のエキスパートのみを利用
入力トークンが「野球」についての内容なら、野球知識に特化したエキスパートを呼び出す、というように、一部のエキスパートだけで効率的に処理できるという利点があります。 - DeepSeekMoE-V3のエキスパート数
通常のMoEモデルが8〜16個のエキスパートを持つのに対して、DeepSeekMoE-V3は256個ものエキスパートを用意し、さらに「シェアドエキスパート」を加えることで安定した共通知識を参照できるようになっています。 - モデルサイズと実効的なパラメータ
DeepSeek-V3の総パラメータ数は6000億(600B)と巨大ですが、推論時には実質370億パラメータ(37B)しか活性化しません。よって推論に必要なメモリ転送量や計算コストが抑えられるのです。
学習と推論の難しさ──MoEの課題
MoEには大きな可能性がある一方、学習や推論の実装には多くの課題があります。
- 学習が不安定
ルーターの選択が誤ると、エキスパートが適切に学習されず性能が伸びない恐れがあります。選択されなかったエキスパートへの誤差伝搬が少なくなる「ハードアテンション問題」も深刻です。 - 大規模分散学習の負荷
2,048台のGPUを分散して動かす際、エキスパートごとに計算の偏りが生じやすく、実行効率が大幅に低下するリスクがあります。デバイス間通信やバッチサイズの管理が難しく、実際に計算機が遊んでしまう事態も起こりえます。 - B/F比(メモリ転送量と計算量の比)の悪化
モデルをスパース化(エキスパートごとの処理を分散)すると、計算量自体は減りますが、メモリ転送のオーバーヘッドが相対的に増大し、GPUの潜在性能を十分に活かせなくなる場合があります。
DeepSeekが行った解決策
DeepSeekはこれらの問題をエンジニアリング面で徹底的に解決し、高い実行効率を実現しています。
- デュアルパイプの採用
フォワードプロパゲーションとバックプロパゲーションをGPU間でオーバーラップさせ、アイドル状態を最小限に抑える工夫です。 - 通信専用のSMコアの活用
1つのGPUに多数のSM(Streaming Multiprocessors)がある中で、一部を通信処理に特化させるカスタムカーネルを手書きすることで、デバイス間のデータ転送を高速化しています。 - FP8 Training
低精度(FP8)での学習は不安定になりがちですが、細かいブロック単位で量子化することで精度・安定性・速度のバランスを取っています。 - 大規模推論クラスタの推奨
推論時には理論上、370億パラメータ相当のメモリ・計算コストで済むとはいえ、スパース性ゆえに320 GPUほどの環境が推奨されています。より小規模な構成だとスループットが低下しがちなため、ここも大規模分散が前提となっています。
ハードウェアデザインへの提案
DeepSeekの論文では、通常あまり見かけない「ハードウェアへの要望」が記載されていることも話題です。
- 通信ハードウェアの強化
現状、通信のために多くのリソースを割かざるを得ないため、GPU内部に専用の通信ユニットを設けてほしいという提案があります。 - FP8でのAccumulation Precision向上
量子化を最大限に活かすため、FP8で演算する際の積和精度やブロック単位の処理がより柔軟に実現できるよう設計を求めています。 - 転置した行列をそのままGEMMできる設計
現在は転置後に再度メモリを読み書きする負荷が大きいため、これを解消できるハードウェアサポートを望んでいるとのことです。
まとめ:新たな選択肢としてのMoEとDeepSeek-V3
DeepSeek-V3は、低コストGPUと先進的なエンジニアリングで、大規模モデルの学習・推論においてフロンティアモデルに匹敵する成果を上げる可能性を示しています。とはいえ、学習の安定化や通信負荷への対処など、エンジニアリングのハードルは依然として高く、推論時にも大規模クラスタを必要とするなど、課題は山積みです。
しかし、これまで大手IT企業の独壇場と見られてきた大規模言語モデルの分野に、新興企業やオープンモデルが大きく食い込んだという事実は、今後のAI業界にとって大いに刺激となるでしょう。高性能なモジュールが「巨大リソース」を必須とする時代は、すでに変わり始めています。
新たなハードウェア設計への提案も含め、DeepSeek-V3のアプローチは今後のAIインフラ開発の方向性を占う上で非常に興味深い事例です。MoEの利点と難しさを把握しつつ、これから訪れる“スパースな大規模モデル”の時代にどのように備えるか──次の一手を検討するうえで、DeepSeekの技術は大いに参考になるはずです。
