

クラウドベースのChatGPTやBardが話題を集める中、自分のPC内で完結する「ローカルLLM(大規模言語モデル)」が静かに革命を起こしています。とくに日本語に対応したローカルLLMは、企業の機密情報保護やプライバシー確保の観点から、ビジネスシーンでの注目度が急上昇中です。
本記事では、一般的なPCでも動作可能になった日本語対応ローカルLLMの最新動向と実際の性能を、具体的な出力例とともに徹底検証します。オフラインでも高品質な日本語生成が可能になった現在、その実用性と導入方法を解説します。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
ローカルLLMとは?—クラウドに依存しない次世代AI基盤
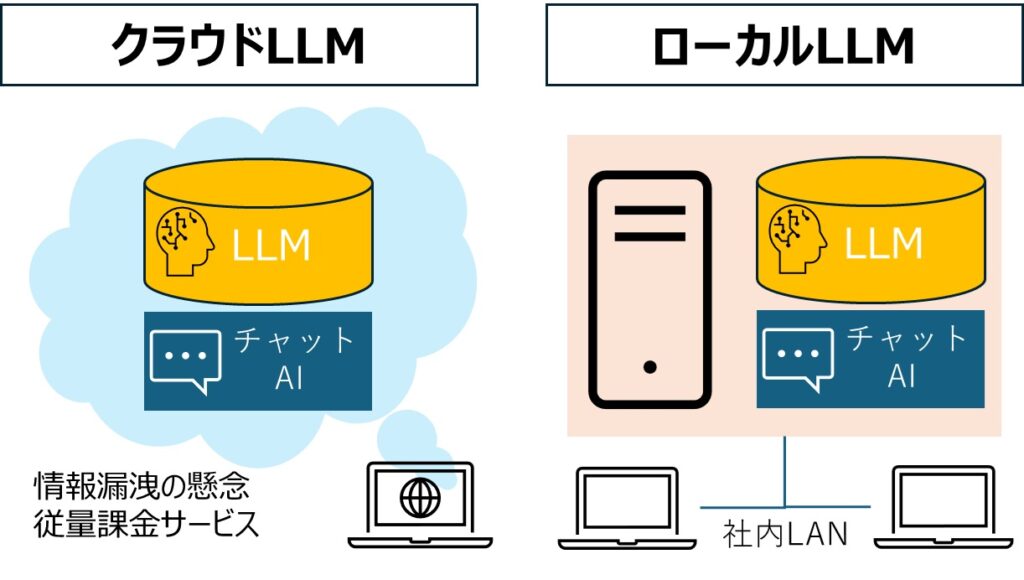
ローカルLLMとは、個人のPCや企業内サーバーなど、インターネット接続を必要としないローカル環境で完結する大規模言語モデルのことです。最大の特徴は以下の3点です。
- インターネット接続不要でオフライン環境でも動作
- データがローカル環境内で処理されるためプライバシー保護に優れる
- 継続的な利用料金が発生しない(初期導入コストのみ)
従来、LLMは高性能なGPUや大容量メモリを必要とし、クラウド上での運用が一般的でした。しかし、技術の進展により、軽量化や量子化が進み、一般的なPCでもオープンソースのLLMモデルを動作させることが可能になりました。この変化が、企業や個人ユーザーにとって新たな選択肢を生み出しています。
注目の日本語対応ローカルLLM—進化する国産AI技術

日本語処理に特化したローカルLLMが続々と登場し、実用レベルに達しています。以下に代表的なモデルを紹介します。
① LLAMA-3-ELYZA-JP-8B-AWQ:日本語特化型の軽量モデル

Meta社が開発したLlama-3をベースに、国内AI企業のELYZA社が日本語対応に特化させた高性能モデルです。最大の特徴は「量子化技術」による軽量化で、一般的なノートPCでもスムーズに動作します。
量子化技術とは
LLMモデルのパラメータやアクティベーションを低精度のビット幅で表現し、メモリ使用量や計算負荷を大幅に削減する技術。精度をほぼ維持したまま、必要リソースを抑えることができます。
② Mistral-Nemo-Japanese-Instruct:実用的な日本語モデル

CyberAgent社が公開した日本語対応モデルで、LM Studio上での利用が推奨されています。日本語の性能が高く、実用的なモデルとして評価されています。
LM Studioとは
ローカル環境でLLMを実行できるオープンソースのソフトウェアです。オフラインでの自然言語処理が可能で、Mac、Windows、Linuxに対応しています。
③ Gemma2 Baku 2B:日本語処理能力が高い

Gemma 2 Baku 2Bは、Google社が公開した大規模言語モデル(LLM)であるGemma 2 2Bを基に、rinna株式会社が日本語能力を強化したモデルです。このモデルは、日本語と英語の学習データ800億トークンを使用して継続事前学習されており、日本語処理能力が向上しています。
これらのモデルは、パラメータ数が26億と比較的少ないため、軽量でありながら高いテキスト生成能力を持ち、推論時のコストパフォーマンスも高いと評価されています。

ローカルLLMの導入ガイド—自分だけのAIアシスタントを構築する

ローカル環境でLLMを稼働させるには、適切なハードウェア構成とソフトウェア設定が不可欠です。以下に、実践的な導入手順を解説します。
3-1. 必要なハードウェア構成
LLMの性能を最大限に引き出すには、とくにGPUの性能が重要です。以下の推奨スペックを参考にしてください。
| コンポーネント | 推奨スペック | 備考 |
|---|---|---|
| GPUメモリ (VRAM) | 8GB以上 | NVIDIA GeForce RTX 3060 (12GB) や RTX 3070 (8GB) が適切 |
| システムメモリ (RAM) | 16GB以上 | 大規模モデル使用時は 32GB 以上を推奨 |
| ストレージ | SSD 500GB以上 | モデルデータ保存用に高速なSSDが必須 |
| 電源ユニット (PSU) | 750W以上 | 安定動作のため余裕を持った電源設計が必要 |
| 冷却システム | 高効率空冷/水冷 | 長時間稼働時の熱対策として重要 |
最新の軽量モデルであれば、GPU非搭載のノートPCでも動作可能なケースがありますが、レスポンス速度や処理能力に制限があります。
2. ソフトウェアの設定
ハードウェアの準備が整ったら、以下の手順でソフトウェアを設定します。
- Pythonのインストール: 公式サイトからPythonをダウンロードし、インストールします。
- 必要なライブラリのインストール:
pipを使用して、以下のライブラリをインストールします。- bashコード
pip install transformers torch
- bashコード
- モデルのダウンロード: Hugging Faceなどのプラットフォームから、使用したいモデルをダウンロードします。日本語対応のモデルとして、Llama-3-ELYZA-JP-8B-AWQやMistral-Nemo-Japanese-Instructなどがあります。
- モデルのロードと実行: 以下のPythonコードを使用して、モデルをロードし、テキスト生成を行います。
- pythonコード
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("モデル名") model = AutoModelForCausalLM.from_pretrained("モデル名") input_text = "こんにちは、今日はどのようにお手伝いできますか?" inputs = tokenizer(input_text, return_tensors="pt") outputs = model.generate(**inputs) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- pythonコード
これらの手順を踏むことで、ローカル環境でLLMを活用した日本語テキスト生成が可能となります。
法人向けのローカルLLM構築サービス
セキュリティの懸念があり、ChatGPTなどの生成AIの利用を制限している会社もあります。
また、企業の業務データを再活用したいという需要もあるため、法人向けのローカルLLM構築サービスが注目されています。ご興味のある方は以下をご覧ください。
実証検証:ローカルLLMの日本語生成能力

理論上の性能だけでなく実際の使用感を確認するため、以下の一般的なスペックのWindows PCを使って各モデルの日本語生成能力をテストしました。
- OS: Windows 11
- CPU: Intel Core i7
- メモリ: 16GB
- GPU: なし(内蔵グラフィックのみ)
特筆すべきは、以下の検証が「GPUなし」の環境で行われている点です。
日本語生成の結果①
以下の画像はGemma2 Baku 2Bのモデルを使った出力事例です。

日本語生成の結果②
以下は、Llama-3-ELYZA-JP-8B-AWQ のモデルを使った出力事例です。

日本語生成の結果③
以下は、Llama-3.2 Vision のモデルを使った出力事例です。

RAG (Retrieval-Augmented Generation) と ファインチューニング (Fine-Tuning) は、自然言語処理のトピックに関連する 2 つの重要な概念です。 ### RAG (Retrieval-Augmented Generation) RAGは、モデルが与えられた入力に対して既存のドキュメントやデータから関連情報を検索し、それを生成した文に組み込む技術です。モデルは、元の入力を基にして新しい文を作成するのではなく、関連情報を検索してそれを使用して文を作成します。 RAGモデルでは、次のようなプロセスが実行されます。 1. 文書検索: モデルは与えられた入力に対して関連するドキュメントやデータを検索します。 2. 情報抽出: モデルは検索結果から関連する情報を抽出します。 3. 生成: モデルは抽出した情報を元の入力に組み込み、新しい文を作成します。 RAGモデルは、特定のタスクやテーマに関する深い理解と知識を提供するのに役立ちます。たとえば、質問回答システムでは、RAGモデルが既存のドキュメントから関連情報を検索し、それを使用して正しい答えを作成できます。 ### ファインチューニング (Fine-Tuning) ファインチューニングは、既存のモデルに特定のタスクやテーマに関するデータで再トレーニングするプロセスです。元のモデルは事前学習済みであり、特定のタスクに対して適切なパフォーマンスを示しますが、ファインチューニングではその知識と能力を特定のタスクに適用するために再度トレーニングします。 ファインチューニングプロセスでは、次のようなステップが実行されます。 1. 既存モデル取得: 元のモデルが事前学習済みで利用可能であることを確認します。 2. データ準備: 特定のタスクやテーマに関するデータを準備し、それを元のモデルに提供します。 3. 再トレーニング: 元のモデルは再びトレーニングされ、特定のタスクに対して適切なパフォーマンスを示すようになります。 ファインチューニングは、既存のモデルに新しい知識や能力を追加することで、そのパフォーマンスを向上させるのに役立ちます。たとえば、質問回答システムでは、元のモデルに質問回答データで再トレーニングすると、より正確な答えを作成できます。 主な違い * RAGモデルは既存のドキュメントから関連情報を検索し、それを生成した文に組み込む技術です。 * ファインチューニングは既存のモデルに特定のタスクやテーマに関するデータで再トレーニングするプロセスです。 どちらのアプローチでも、自然言語処理のパフォーマンスを向上させるのに役立ちますが、目的とアプローチは異なります。
日本語生成の結果④
以下の画像はGemma2 Baku 2Bのモデルを使った、ニュース記事の要約の出力事例です。

東証プライム企業向けに実施された「生成AI導入実態調査」について、要約すると以下のようになります。 この調査によると、2024年時点で東証プライム市場の1640社のうち、ChatGPTのような生成AIを導入済みの企業は全体の約14.9%にあたる約245社です。これは前年の約10%から大幅に増加しており、企業が生成AIに対する関心と活用を本格的に始めていることがわかります。 主な調査結果は以下の通りです: * **社内用生成AIの普及が進む**: 導入企業のうち、チャットボットではなく社内用生成AI(自社独自のシステム)を導入したのは55.3%で、最も多い利用用途となっています。 * **セキュリティと利便性の向上**: 地方銀行は社内専用の生成AIプラットフォームを採用し、機密情報を含む行内のデータを安全に活用しながら業務効率化を実現しています。 * **RAG技術の活用が拡大**: 企業は自社のデータ資産を統合した社内生成AIを導入し、より高度で精度の高い意思決定や情報提供が可能になっています。 * **人材育成が重要**: 企業はリスキリングなどを通して、組織全体でAIを活用できるように人材育成に取り組んでいます。 この調査結果は、企業による生成AIの積極的な利用が加速していることを示しており、今後の競争優位性獲得や業務効率化に大きな影響を与える可能性があります。
元記事:東証プライム企業生成AI導入実態調査について
参考(ChatGPT4oに同じ記事を要約してもらった結果)

ローカルLLMを用いた日本語生成の実力は、モデルやハードウェア環境によって異なります。たとえば、Llama-3-ELYZA-JP-8B-AWQを使用した場合、20~30秒程度で高品質な日本語テキストを生成することが報告されています。
一方、Mistral-Nemo-Japanese-Instructは、日本語の性能が高く、実用的なモデルとして評価されています。ただし、利用にはLM Studioの導入が必要となります。
LM Studioを利用したローカルLLMの日本語出力事例

日本語生成の結果⑤
Cyberagent / Mistral-Nemo-Japanese-Instructの日本語出力

日本語生成の結果⑥
Llama-3-ELYZA-JPの日本語出力

ローカルLLMを用いた日本語生成:まとめ

ローカルLLMを用いた日本語生成は、技術の進展により一般的なPCでも可能となり、セキュリティやプライバシーの観点からも注目されています。
最近では、スマホでも動かせると言われるローカルLLMのモデルも登場しています。ご興味のある方は以下をご覧ください。

