

ローカルLLMの衝撃—Phi‑4・Gemma 2・Qwen 3の社内活用
クラウド時代に「わざわざ社内サーバーでAIを回す意味なんてあるの?」——もしそう感じたなら、本稿は皆さまの固定観念を覆す一篇になります。Microsoft Phi‑4 や Gemma 2 のような小型 LLM が急速に進化した今、オンプレミスでも ChatGPT 級の体験を実現できます。しかも情報漏洩リスクを最小化し、IT 部門の稟議をすり抜けて “今日から試せる” 導入ルートまで用意できます。
本記事を読み終えるころには、皆さまは「自社 PC 1台で始め、必要に応じてクラスターへシームレスに拡張する」具体的な設計図を手にしているはずです。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
クラウド全盛でもローカルが再評価される理由

生成 AI ブームの副作用として、SaaS に預けたプロンプトや業務データがどこで誰に触れられるか不透明になりました。法務・監査部門が神経質になるのは当然ですが、現場がすぐ使えなければ AI 導入は形だけで終わります。
ここで脚光を浴びるのが ローカル・ファースト という発想です。小規模でも高性能な LLM が続々公開され、GPU 1枚・RAM 32 GB 程度でも社内 QA ボットやレポート自動生成をこなせます。つまり「クラウドでしか動かない」は過去の常識になりつつあります。さらに端末内完結ゆえに個人情報や知財を外部に出さず、EU‐GDPR の越境データ制限や日本の APPI 対応も一挙にクリアできます。
3つのオンプレ形態とアプリ設計の勘所
オンプレといっても「① IT 部門管理サーバー」「② 部署設置サーバー」「③ ユーザー PC」の三層に大別できます。
- ① は高可用性や RBAC などエンタープライズ機能を盛り込める反面、導入まで数か月の社内審査が壁になります。
- ② は Mac Mini や DGX Spark を部門費で購入すれば済むため機動力に優れますが、運用は部門内で完結しなければ続きません。
- ③ は最速導入の切り札ですが、インストール手順が複雑ですと即座に放棄される恐れがあります。
したがって、最初は③で “魔法体験” を提供し、採用決定後に②→①へ水平展開する設計が合理的です。
ローカル導入を可能にするミニマム構成
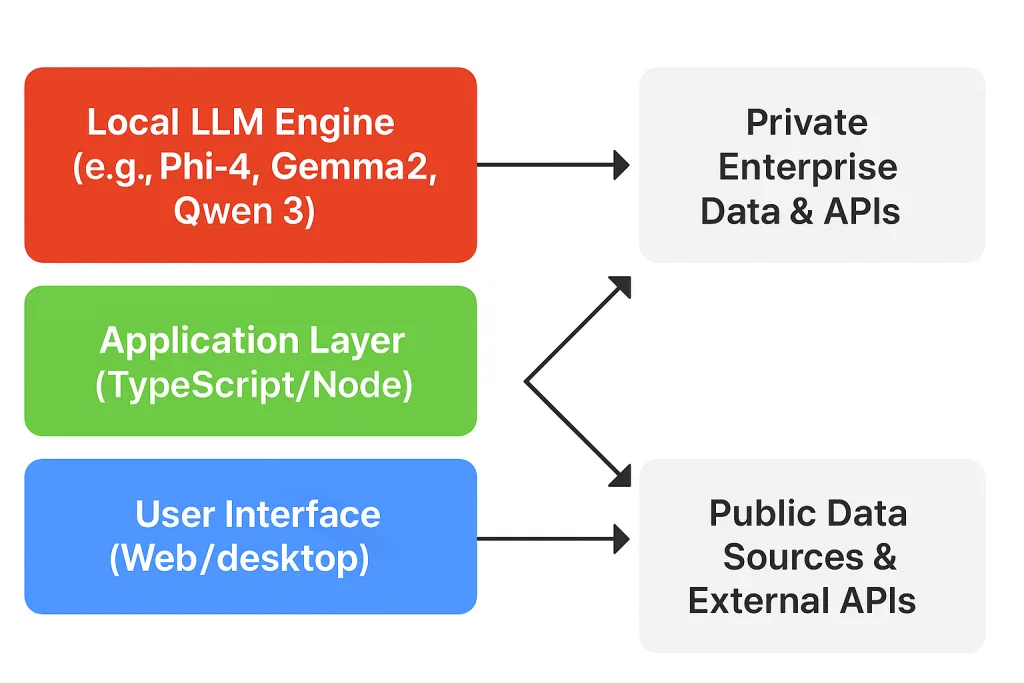
ユーザー PC 1台で回すためには、(a) GPU もしくは高速 CPU、(b) コンテナ不要で導入できる実行環境、(c) UI/UX が一貫したフレームワークが鍵となります。GraphAI は TypeScript 製 npm パッケージとして提供され、「npm i graphai && graphai dev」 と入力するだけで即起動できます。バックエンド(Node.js)とフロント(React/Next)は同一コードベースに同居し、OS は Windows/Mac/Linux を問いません。LLM 本体は GGUF 形式で自動ダウンロードでき、メモリ内ロードも選択できますので 「管理者権限が不要」 という実務上のメリットも大きいです。
部署サーバーへのスケールアップシナリオ
ローカル検証で ROI を示せたら、次は部門サーバーへ載せ替える段階です。ここでは AI モデルと Node バックエンドだけを Mac Studio や小型 GPU サーバーに移設し、フロントは各ユーザーがブラウザでアクセスする構成を採用します。モデル更新は DL リンクを環境変数で切り替えるだけで済みます。キャッシュ共有用に Redis を挟み、トークン制限を超えそうなジョブはキューイングして GPU 時間を平準化します。この方式ならインフラ知識が乏しい部門でも “電源と LAN に挿すだけ” で運用が回ります。
IT 部門クラスターに耐えうる拡張案
全社展開が決まれば、Kubernetes や Nomad で複数 GPU ノードを束ね、モデルロードをオートスケールさせます。GraphAI は REST/GraphQL の二系統 API を持つため、Istio や Traefik に載せて Zero‑Trust 認証をかければ SaaS 同等のセキュリティを確保できます。データは社内 MinIO に暗号化保存し、オブザーバビリティには Prometheus+Grafana を採用します。ここまで進めてもアプリ実装側はほぼコード変更ゼロで済みますので、ローカル・ファースト設計の真骨頂といえます。
実践ロードマップ:今日から始める5ステップ
- 開発 PC に GraphAI を npm インストールし、GGUF 版 Phi‑4‑mini をロードします。
- 社内ドキュメント 50 件を txt 化し、埋め込みを生成して SQLite に格納します。
- QA チャット UI を立ち上げ、業務質問で回答品質を検証します。
- GPU リソース要件と応答遅延をレポート化し、部門長を説得します。
- Mac Studio+RTX 5000 環境へ移設し、ブラウザ共有 URL を配布します。
この流れであれば稟議を待つ前に成果物を可視化でき、費用対効果をデータで示しやすいです。
まとめ:ローカル・ファーストは“面倒”ではなく“最短ルート”
クラウド AI は便利ですが、企業が本当に欲しいのは 機密を握ったまま素早く試せる AI です。小型 LLM と GraphAI の組み合わせは、USB メモリ感覚で試し、データセンター規模まで伸びる可変性を提供します。つまりローカル・ファーストはレガシー回帰ではなく、現代のエンタープライズに最もフィットする “攻めの戦略” です。明日も SaaS の審査待ちで時間を浪費するくらいなら、まずは皆さまのラップトップで LLM を走らせてみてください。ビジネスを変える第一歩は、意外と机の上に転がっています。
参考)週刊Life is beautiful 2025年5月13日号
