Meta(Facebook、Instagram、WhatsApp、Quest VRの親会社)は12月6日、同社の生成AI担当VPであるAhmad Al-Dahle氏がSNS「X」で、最新のオープンソース多言語大規模言語モデル(LLM)「Llama 3.3」をリリースしたと発表しました。この記事ではLlama 3.3について深く掘り下げて解説しましょう。
Llama 3.3は巨大モデルの性能を小型化で実現
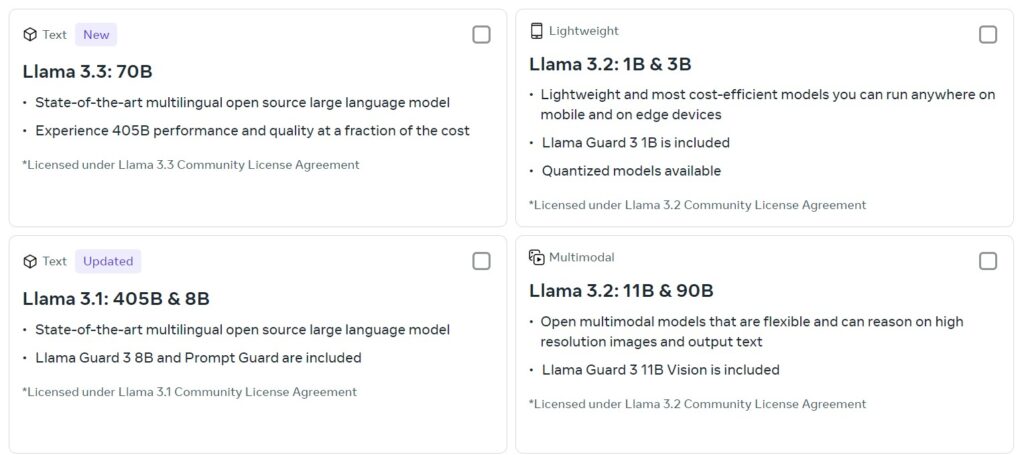
70Bパラメータで405B同等の性能を実現
Llama 3.3は70億(70B)のパラメータを持ちながら、2024年夏に登場した405Bパラメータ版の「Llama 3.1」とほぼ同等の推論性能を発揮するとされています。それにもかかわらずGPUメモリなどのリソース消費は大幅に削減され、導入・運用コストが低いのが特長です。
MetaのAIチームは「Llama 3.3はテキストベースの幅広いユースケースにおいて優れた性能と品質を提供しながら、推論(推定)に必要なGPUメモリや電力コストを最小限に抑えられる」とコメントしています。
Llama 3.3 70Bのコンテキスト長は12万8000で、対応言語は英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語です。
Llama 3.3と3.2、3.1の比較について
以下に、Llama 3.3、Llama 3.2、Llama 3.1の主な特徴を比較した表を作成しました。
| 特徴 | Llama 3.1 | Llama 3.2 | Llama 3.3 |
|---|---|---|---|
| パラメータ数 | 70B、405B | 1B、3B、11B Vision、90B Vision | 70B |
| モーダル対応 | テキストのみ | マルチモーダル(テキスト、画像) | テキストのみ |
| コンテキストウィンドウ | 最大2,048トークン | 最大128kトークン | 最大128kトークン |
| パフォーマンス | 405Bモデルは高性能だが、計算コストが高い | マルチモーダル対応で、エッジデバイス向けの軽量モデルも提供 | 70BモデルでLlama 3.1の405Bモデルに匹敵する性能を発揮し、推論コストが低い |
| 主な用途 | テキスト生成、対話型AI | 画像解析、マルチモーダルタスク、エッジデバイスでの利用 | テキスト生成、対話型AI、低コストでの大規模言語モデルの利用 |
| 日本語対応 | 公式サポート外だが、対応可能 | 公式サポート外だが、対応可能 | 公式サポート外だが、対応可能 |
| リリース日 | 2024年7月 | 2024年9月 | 2024年12月 |
- Llama 3.1は、70Bおよび405Bのパラメータモデルを提供し、特に405Bモデルは高い性能を持っていますが、計算コストが高くなります。
- Llama 3.2は、マルチモーダル対応が強化され、1Bや3Bの軽量モデルはエッジデバイスでの利用に適しています。
- Llama 3.3は、70Bのパラメータ数でありながら、Llama 3.1の405Bモデルに匹敵する性能を発揮し、推論コストが低減されています。
これらのモデルはすべて日本語を公式にはサポートしていませんが、対応は可能とされています。
Llama 3.3の大幅なGPUコスト削減効果

一例として、Substratusのブログでは、405BパラメータのLlama 3.1を動かすのに必要なGPUメモリは243GBから1944GBと試算されています。
一方、70Bパラメータの旧Llama 2では42GBから168GB程度が必要とされており、一部の事例では4GBほど、さらにMシリーズチップ搭載のMac数台で動かせるとの報告もあります。
初期コストを大幅に削減できる可能性も
同様の推論が成り立つなら、Llama 3.3を導入する際には最大約1940GBものGPUメモリを節約可能という計算になります。
たとえば、Nvidia H100(80GB)を前提とすればGPU負荷が24分の1に圧縮でき、H100 1台あたり推定2万5,000ドル(約300万円)とすれば、60万ドル(約6,000万円)もの初期コストが削減できる可能性もあります。

マルチリンガル対応と高精度推論
Llama 3.3はドイツ語、フランス語、イタリア語、ヒンディー語、ポルトガル語、スペイン語、タイ語など、多言語対応を強化。マルチリンガルな推論タスク「MGSM」において91.1%の精度を達成し、英語以外の言語サポートも充実しています。
また、Amazonの新モデル「Nova Pro」を含む競合と比較したベンチマーク結果でも、Llama 3.3は多言語対話や推論などで優位とされ、HumanEvalによるコーディングタスクでは若干劣るものの、総合的には高い評価を受けています。
大規模データによる学習とエネルギー効率
Llama 3.3は公開データから得た15兆(15T)トークンを使って事前学習を行い、そこから2,500万(25M)以上の合成データによるファインチューニングを実施しています。
H100-80GBを用いたGPU稼働時間は3,930万(39.3M)時間におよぶ大規模プロジェクトでしたが、Metaは再生可能エネルギーを活用し、トレーニング時の温室効果ガス排出を実質ゼロに抑えたとしています。
場所ベースの排出量はCO2換算で11,390トンにのぼるものの、再生可能エネルギーの取り組みを通じて相殺を図りました。

Llama 3.3のコスト効率と環境配慮の両立
本モデルは、トークン生成コストが100万トークンあたり0.01ドル(約1.1円)程度まで低減されており、GPT-4やClaude 3.5といった業界トップクラスのLLMと比べてもコスト競争力が高いとされています。
長い文章(最大128kトークン、約400ページ分のテキスト)を扱えるコンテキストウィンドウや新たに導入されたGrouped Query Attention(GQA)による拡張性・推論効率の向上も特徴です。
加えて、Llama 3.3はRLHF(人間のフィードバックを用いた強化学習)とSFT(教師あり学習)を併用して安全性と有用性を高める調整を行っており、現実的なアプリケーションでも問題のある入力に対しては適切に拒否し、支援的かつ自然な回答を提供できるよう設計されています。

オープンソースライセンスと利用制限
Llama 3.3は「Llama 3.3 Community License Agreement」のもとで提供され、非独占かつロイヤリティフリーで利用、複製、配布、改変が可能です。
ただし、「Built with Llama」のようなクレジット表記や、違法行為や有害コンテンツ生成、サイバー攻撃などを禁じる「Acceptable Use Policy」への同意が必要になります。
さらに、月間アクティブユーザーが7億人を超える組織については、Metaと直接契約し商業ライセンスを取得する必要があります。
Llama 3.3のダウンロードと利用方法
現在、Llama 3.3はMeta公式サイト、Hugging Face、GitHubなど、複数のプラットフォームを通じてダウンロードが可能です。
研究者や開発者向けには、Llama Guard 3やPrompt Guardなどのサポートツールも提供され、安全かつ責任あるモデル運用を後押しします。
多言語LLM Llama 3.3:まとめ

Llama 3.3はサイズ・コスト・環境負荷のすべてを抑えつつ、高い多言語対応と柔軟な性能を誇り、オープンソースコミュニティに大きな恩恵をもたらすと期待されています。
大規模AIをより手軽に活用したい企業や研究者にとって、Llama 3.3は注目すべき新しい選択肢となるでしょう。
参考)Llama公式サイト