

大量のテキストデータでトレーニングされているChatGPTは、さまざまな用途に使用できる仕様です。しかし、ファインチューニングすることで、特定の用途に特化させることもできます。
この記事では、ChatGPTをより有効活用するためのファインチューニングについて解説します。
ChatGPTをファインチューニングするメリット

特定のタスクに特化したモデルを作成できる
ファインチューニングを行うことで、モデルのパラメータを特定のタスクに適した形に微調整することができます。これにより、ChatGPTのパフォーマンスを向上させることが可能です。
2023年10月現在、ファインチューニングが可能なのはGPT-3.5 Turboです(GPT4のファインチューニングに関しては「まもなく発表」とのこと)。
GPT-3.5 Turboをファインチューニングすることで、特定のタスクではGPT-4以上の能力を示すことが可能になります。
ファインチューニングの具体例
例えば、ChatGPTを医療用チャットボットにする場合、医療に関するテキストデータでファインチューニングを行うことで、より的確な回答を生成できるようになります。
また、ChatGPTをニュース記事の要約生成に使用する場合は、ニュース記事のデータでファインチューニングを行うことで、より正確で簡潔な要約を生成できるようになります。
ファインチューニングの効果が期待できる分野

ChatGPTのファインチューニングがどのような分野で効果を発揮するのか、具体例を紹介します。
専門的な知識を要する分野
医学、法律、工学など、特定の専門用語や概念が多く存在する分野でファインチューニングを行えば、これらのドメイン特有の言い回しや知識に関する回答の精度を向上させることが可能です。
カスタマーサポート
特定の製品やサービスに関連する質問やトラブルシューティングに対する回答の品質を向上させることが可能です。製品固有の情報やFAQをデータセットとしてファインチューニングを行います。
教育と学習
特定の教科書や教材に基づいてモデルをファインチューニングすることで、より学習内容に合わせたサポートや説明を提供できます。
ファインチューニングのやり方

ファインチューニングを行うには、以下の手順を踏みます。
APIの取得
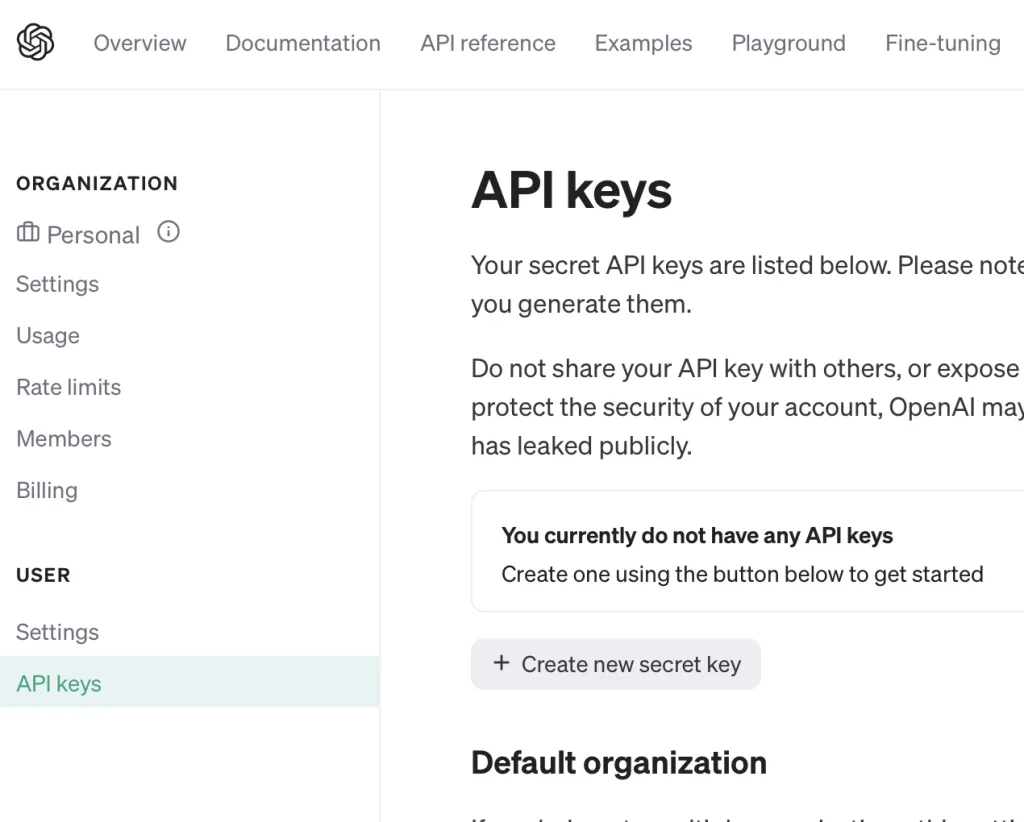
ファインチューニングにはOpenAIからAPIを発行してもらう必要があります。こちらのサイトから、「+Create new secret Key」と書かれたグレーのボタンをクリックすることで、APIキーが発行されます。
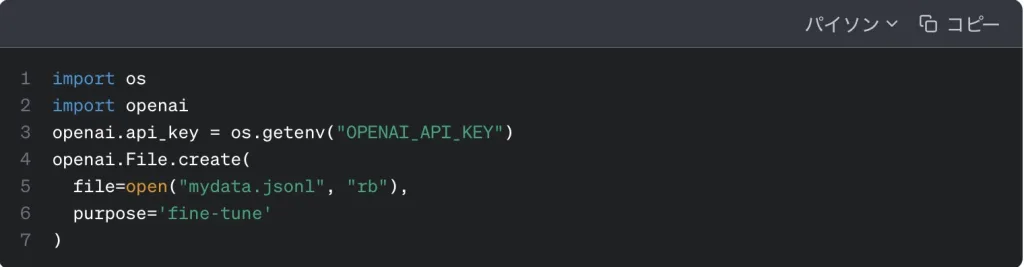
データセットを用意する
特定のタスクでのパフォーマンスを向上させるために使用するデータセットを集めます。この際にJSON(JavaScript Object Notation)を使用します。データセットする際のフォーマットは以下の画像を参考にしてください。

用意したデータセットはOpenAIのサーバにアップロードします。
ファインチューニングの実行
準備したデータセットを使用して、モデルをファインチューニングします。
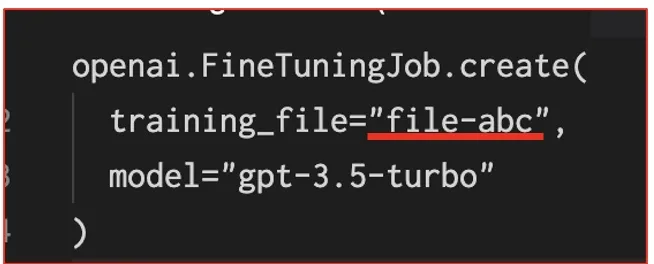
上記の画像の赤線部分「file-abc」の部分は、データセットで集めたファイル名にします(今回はfile-abcとしました)。
なお、ファインチューニングの詳細はOpenAIの公式ページをご覧ください。
トレーニングが完了するまで数十分かかることもあります。完了するとOpenAI Playgroundでファインチューニングしたモデルを使用できます。
ファインチューニングを行う際の注意点

ファインチューニングを行う際には、以下の点に注意する必要があります。
データセットの偏り
データセットが偏っていると、偏った結果を生成する可能性があります。
過学習を避ける
モデルの過学習モデルがトレーニングデータに過度に適応してしまうと、新しいデータに対してうまく適用できなくなる可能性があります。
適切なインフラを整備
大規模なモデルのファインチューニングはコンピューティングリソースが多く必要となるため、適切なインフラを整えることが必要です。
料金がかかる
gpt-3.5-turboのファインチューニングにかかる料金は以下のとおりです。
| 学習 | 入力 | 出力 | |
| 1,000トークンあたりの費用 | 0.008ドル | 0.012ドル | 0.016ドル |
まとめ

ChatGPTのファインチューニングは、特定の用途に特化した性能を向上させるための有効な手法です。ただし、データセットの偏りやモデルの過学習などの注意点もあるので、ファインチューニングを行う際には、これらの注意点を理解した上で適切な方法で行ってください。
また、自分達でファインチューニングをするのが難しい場合は、お気軽に私たちGPT MASTERにお問い合せください。
