
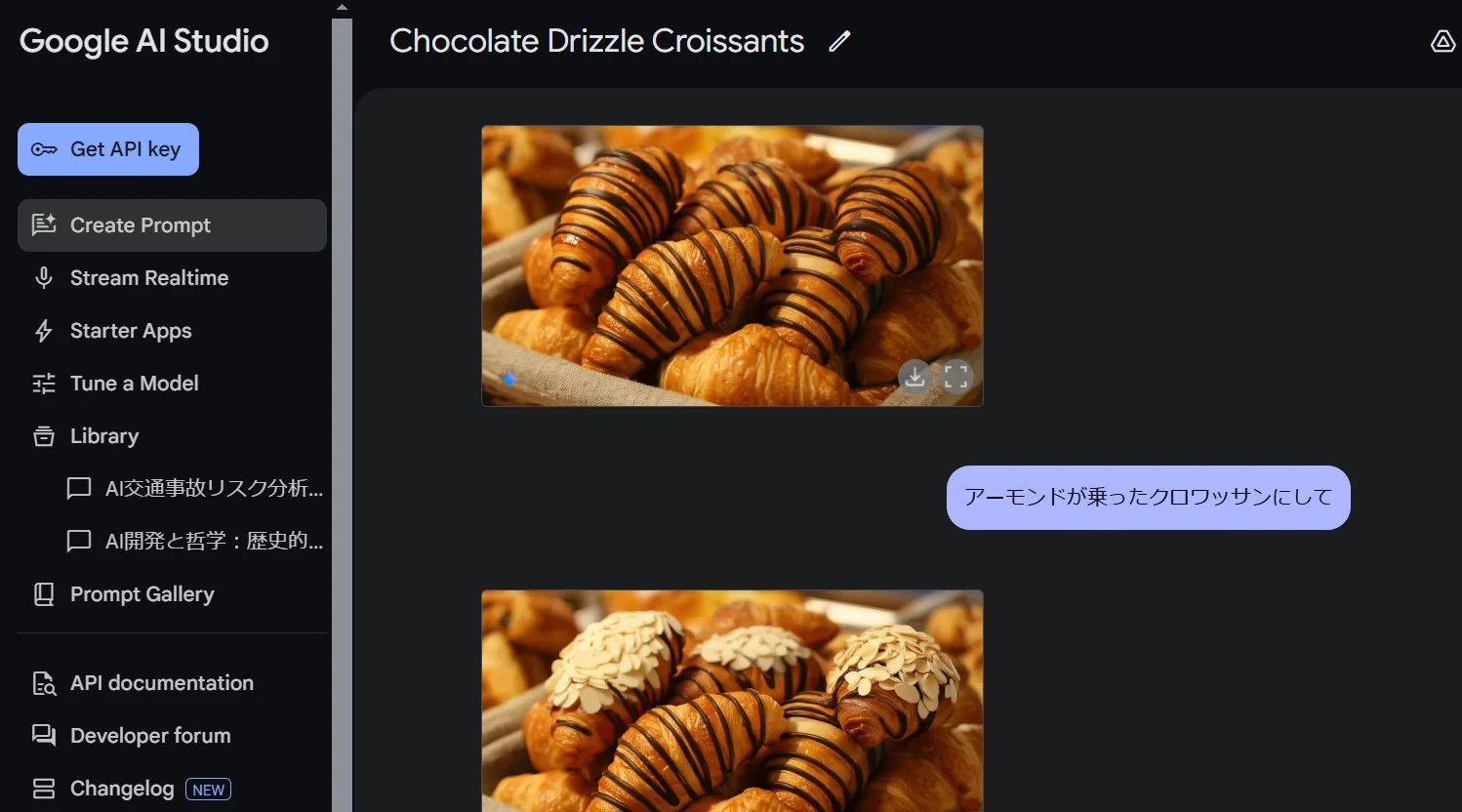
この記事では「テキスト生成」と「画像生成」の両方をこなす新世代AI「Gemini 2.0 Flash」について詳しく紹介します。
1分でわかる!Gemini 2.0 Flashの魅力
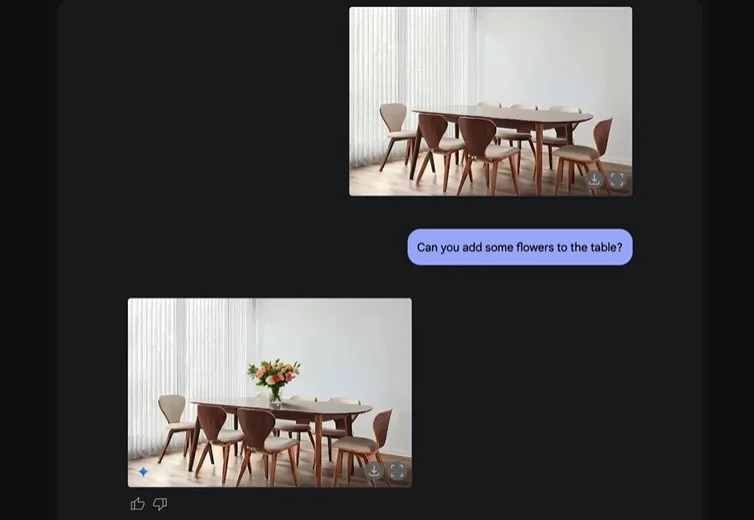
まずはこちらの画像をご覧ください。
右上は何の変哲もない「テーブルの画像」です。この画像に「テーブルの上に花を乗せて」と指示をすると、「テーブルに花が飾られた画像」を作ることができます。
このようにGoogleが新たに発表した「Gemini 2.0 Flash」は、テキストと画像を単一モデル内で生成・編集できるマルチモーダルAIです。
従来、多くのAI画像生成ツールは拡散(ディフュージョン)モデルなどを別途連携させて、テキストの指示から画像を生成していましたが、Gemini 2.0 Flashはテキストと画像を同時に扱えるため、ユーザーの指示に対しより正確で、一貫性の高い結果を実現する点が最大の特徴です。
発表の背景と競合状況
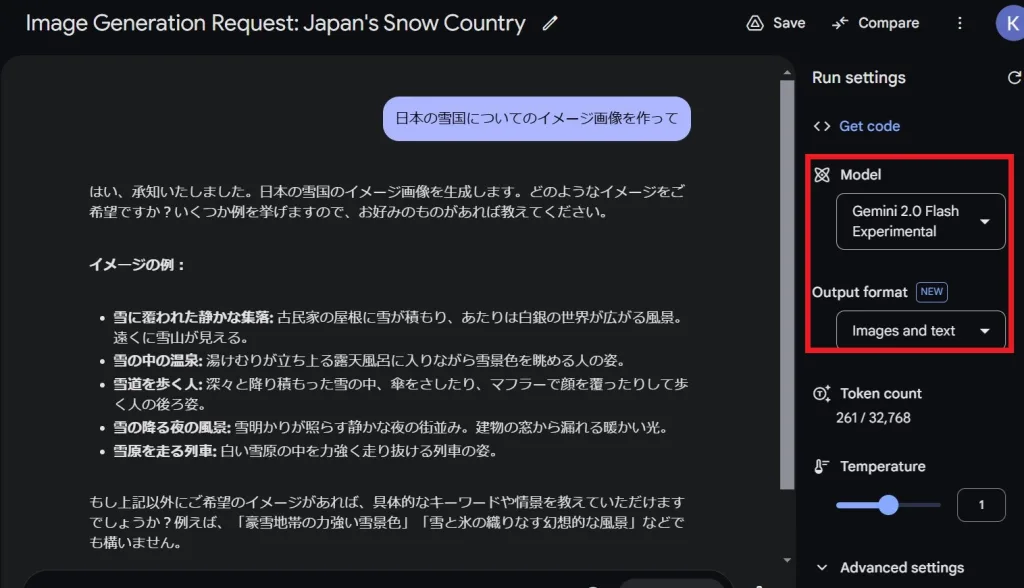
2024年12月に初公開されたGemini 2.0 Flashは、当初はマルチモーダル入力や推論機能を備えつつも、一般ユーザー向けのネイティブ画像生成はまだ実装されていませんでした。今回の実験版リリース「gemini-2.0-flash-exp」により、多くのユーザーや開発者が実際に画像生成機能を試せるようになり、SNS上でも大きな話題を呼んでいます。
一方、競合であるOpenAIのGPT-4oは以前から画像生成機能を予告していたものの、まだ一般公開されていません。こうした状況下でGoogleは、いち早くネイティブ画像生成を実装し公開したことで、マルチモーダルAIの開発競争において一歩リードしていると言えます。
Gemini 2.0 Flash:注目の機能は?
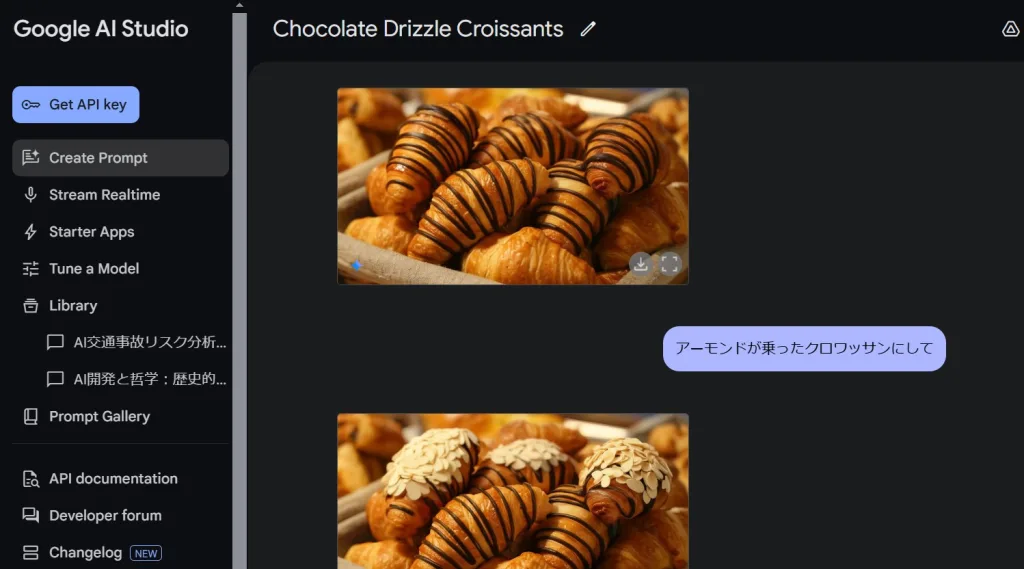
- テキスト&イメージの一貫したストーリーテリング:キャラクターやシーンを保ちながら物語を生成できるため、イラストつきのストーリー作成に適しています。ユーザーのフィードバックに応じてスタイルや内容を柔軟に変更可能です。
- 対話型の画像編集:自然言語によるマルチターン編集が可能で、元画像を細かく修正しながら仕上げていけます。たとえば「もう少しチョコソースを増やして」や「人物の表情を笑顔にして」など、対話的なアプローチでリアルタイムに修正を加えられます。
- 広範な知識ベースによる文脈理解:他の画像生成モデルよりも背景知識が豊富で、実在する食材や調理法などの現実的な情報を加味した画像生成が期待できます。たとえば、レシピを詳細な映像で表現したり、歴史的背景を踏まえたカラー化に活用することも可能です。
- テキスト描画の向上:従来の画像生成AIではテキストが崩れたり誤字が多発する問題がありましたが、Gemini 2.0 Flashは文字をより正確に描画できるとされています。これにより、広告や招待状など、文字を含むビジュアルの作成にも活用できます。
実際の使用例とユーザーの反応
Google AI Studioで試してみたところ、非常に早いスピードで画像を修正してくれます。しかも、前の画像やスタイルを再利用しつつ、微妙に調整などができるのがとても便利です。

- キャラクターイラストの統一感:ピクセルアート風のスタイルを一度生成したら、以降は同じスタイルで新しい構図を簡単に作成できる事例が報告されています。
- 高速かつ直感的な画像修正:「チョコレートソースをかける」「キャラクターの手を上げる」といった簡単な指示で、部分的な編集をすばやく行える点が高く評価されています。
- 白黒写真のカラー化:歴史的資料のカラー復元や、クリエイティブな作品への応用など幅広い可能性があると注目されています。
Twitter(X)上では「OpenAIのGPT-4oより早くネイティブ画像生成を体験できる」といった喜びの声が多く、過去にOpenAIで働いていたエンジニアがGoogle AI Studioでの使い勝手をアピールするなど、各所でポジティブな意見があがっています。
企業・開発者が注目すべきポイント

マーケティングやデザイン業務への活用
広告バナーやSNS用の画像をテキストプロンプトだけで生成できるため、デザイナーの負担軽減やスピーディな制作が期待できます。さらに正確なテキスト表示が可能であることは、販促やパッケージデザインでも大きな利点となるでしょう。
開発フローの簡素化
従来はテキストと画像を別モデルで処理していたため、API連携やトランスフォーマーパイプラインの構築が複雑でした。しかし、Gemini 2.0 Flashなら単一モデルで対応できるので、開発効率の向上や統合的なAIシステムの構築が容易になります。
新しいプロダクティビティツールへの応用
プレゼン資料の自動作成や、契約書のイラスト化、商品写真のバリエーション生成など、ユーザーが必要なビジュアルをAIと対話しながら即時に整えられる仕組みづくりが可能です。UI/UXの試作段階からAIが画像を補助してくれるため、開発サイクル全体を加速できます。
Gemini 2.0 Flashの具体的な導入方法
Gemini APIを通じて、以下のようなPythonコードを利用しながら「gemini-2.0-flash-exp」の機能を試せます。
たとえば、3Dデジタルアート風のカメの物語をテキストと画像で同時に出力するには、下記のようなコード例が公開されています。
from google import genai
from google.genai import types
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash-exp",
contents=(
"Generate a story about a cute baby turtle in a 3D digital art style. "
"For each scene, generate an image."
),
config=types.GenerateContentConfig(
response_modalities=["Text", "Image"]
),
)このようにシンプルなプロンプトでストーリーテキストと画像をワンストップで生成できるのが強みです。要件や用途に合わせて、より複雑な指示や追加の編集リクエストに応じてAIが即座に応答してくれます。
Gemini 2.0 Flash:まとめ

Gemini 2.0 Flashは、マルチモーダルAIという新たなステージでGoogleが一歩先を行く技術を披露した例といえます。テキストと画像を一貫して扱えるため、クリエイティブな応用だけでなく、企業のマーケティングや開発現場での効率化にも大きく貢献する可能性があります。
OpenAIなどの競合モデルと比べても公開の迅速さが目立ち、今後はさらなる機能強化や普及が見込まれるでしょう。最先端のAI技術を有効活用したいと考えるビジネスパーソンや開発者にとっては、いま最も注目すべきサービスの一つです。
参考)Experiment with Gemini 2.0 Flash native image generation

