
DeepSeek-R1は、プライバシーを確保しながら高性能な自然言語処理を実現できる大規模言語モデル(LLM)です。クラウドサービスに依存せず、自分のPC上でAI機能を活用したい方にとって理想的な選択肢となっています。
本記事では、軽量なツールであるOllamaを使って、DeepSeek-R1を簡単にローカル環境で稼働させる方法を、初心者にもわかりやすく解説します。とくに日本語対応モデルについても詳しく紹介しますので、自分専用のAIアシスタントを構築したい方は、ぜひ参考にしてください。
DeepSeek-R1をローカルで実行するためのOllamaセットアップ手順
1. システム要件の確認
- オペレーティングシステム:macOS、Linux、またはWindows
- ハードウェア:
- RAM:最低8GB(推奨16GB以上)
- GPU:NVIDIA GPU(CUDA対応)を推奨。ただし、GPUがない場合でもCPUでの実行は可能ですが、パフォーマンスは低下します。
- ディスク容量:モデルサイズに応じて10GB以上の空き容量
なお、今回はGPUを搭載していないノートPCでOllamaを実行しました。
2. Ollamaのインストール
Ollamaの公式サイトからアプリケーションをダウンロードしてインストールできます。MacOS、Linux、Windowsに対応しています。
または、ターミナルを開き、以下のコマンドを実行してOllamaをインストールします:
curl -fsSL https://ollama.com/install.sh | sh
インストールが完了したら、バージョンを確認して正しくインストールされたことを確認します:
ollama --version
3. DeepSeek-R1モデルのダウンロード
Ollamaを使用して、必要なDeepSeek-R1モデルをダウンロードします。Windowsであれば、「ターミナル」で「ollama run deepseek-r1」とコマンドを打つことで、自動的にモデルのインストールが開始されます。
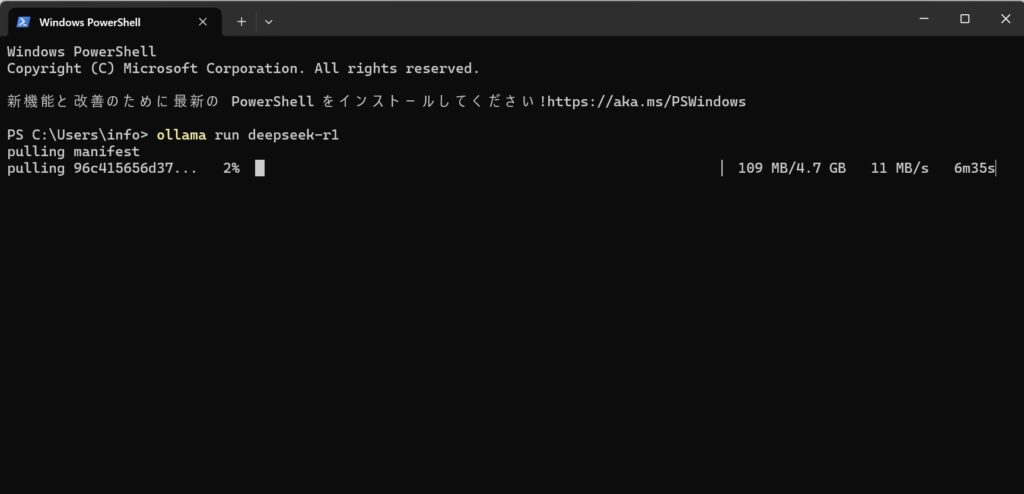
DeepSeek-R1は、パラメータ数の異なる複数のバージョンが提供されています。パラメータ数が多いほど高性能ですが、必要なコンピュータリソースも増加します。お使いの環境に合わせて最適なモデルを選択しましょう。
1.5Bモデル(軽量版):`ollama run deepseek-r1:1.5b`
最小限のリソースで動作し、基本的な会話や簡単なタスクに適しています
7Bモデル(標準版):`ollama run deepseek-r1:7b`
バランスの取れた性能で、一般的な用途に推奨されます
14Bモデル(高性能版):`ollama run deepseek-r1:14b`
より複雑な推論や詳細な応答が必要な場合に適しています
4. モデルの実行
モデルのダウンロードが完了したら、以下のコマンドでOllamaサーバーを起動します:
ollama serve
別のターミナルウィンドウを開き、以下のコマンドでモデルを実行します:
ollama run deepseek-r1:<モデル名>
例えば、7Bモデルを実行する場合:
ollama run deepseek-r1:7b
5. プロンプトの入力
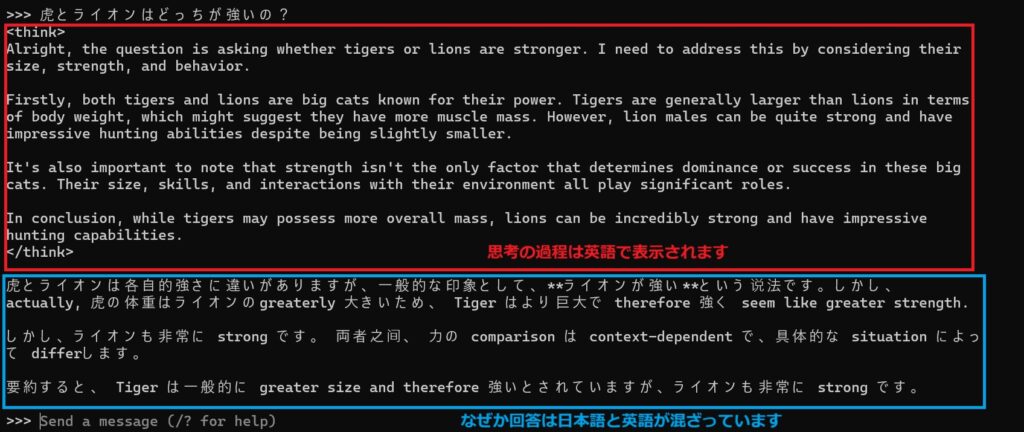
モデルが起動すると、ターミナル上でプロンプトを入力してモデルと対話できます。たとえば、「虎とライオンはどっちが強いの?」と入力すると、モデルからの応答が得られます。
モデル別パフォーマンス比較
DeepSeek-R1:7b(標準モデル)の場合
- 思考プロセスは英語で表示されました
- 回答は日本語と英語が混在しており、一貫性に欠ける結果となりました
DeepSeek-R1:8b の場合
- 同じ質問に対して、より自然な日本語で回答を生成
- 7bモデルと比較して明らかに日本語処理能力が向上していました

日本語に対応したモデルを試してみたら
サイバーエージェントは、中国のAI企業DeepSeekが開発した大規模言語モデル「DeepSeek-R1」の蒸留モデルを基に、日本語データで追加学習を行った「DeepSeek-R1-Distill-Qwen-14B/32B-Japanese」を公開しました。このモデルは日本語処理能力を大幅に向上させています。
このモデルは、Hugging Face上でMITライセンスのもと無料で提供されており、日本語での自然言語処理能力を強化しています。モデルのダウンロードサイズは10GBほどですが、インストールしてみました。
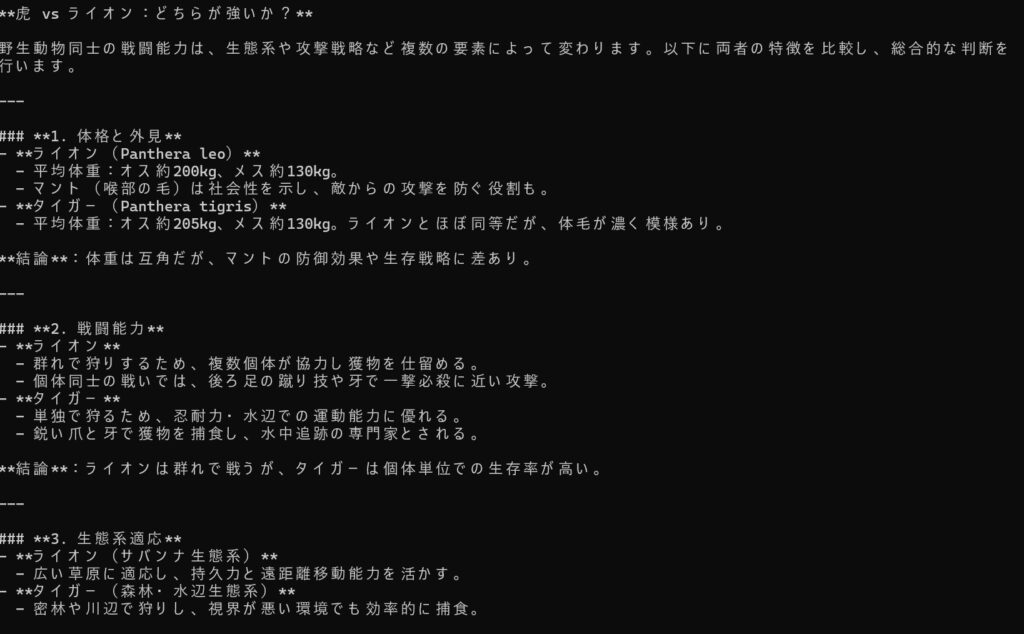
ollama run hf.co/bluepen5805/DeepSeek-R1-Distill-Qwen-14B-Japanese-gguf:Q5_K_Mなんと、日本語でしっかりと考えてくれたうえで、回答してくれました。

その他の日本語対応モデル
2025年1月29日、Lightblue株式会社は日本語版のDeepseek R1を公開しました。このモデルは日本語での思考が得意なため、日本人ユーザーにとって非常に使いやすい点が大きな魅力です。
また、DeepSeek R1の7B Qwen Distilをもとに学習していることで軽量化が実現され、個人のパソコンでもスムーズに動かせるほどのコンパクトさを備えています。
さらに、実験ではR1の7B Qwen Distilよりも日本語の数学問題を正確に解くことが確認されており、優れた知能を持ち合わせているようです。
LM StudioでDeepseek R1の日本語モデルを使う方法

LM StudioでDeepseek R1の日本語モデルを使ってローカルLLMを構築する方法もありますので、そちらは以下の記事で解説しています。
注意事項
- リソース管理:モデルのサイズが大きいほど、必要なシステムリソースも増加します。システムの性能に応じて適切なモデルを選択してください。
- GPUの活用:GPUを使用することで、モデルの実行速度が大幅に向上します。NVIDIAのCUDA対応GPUをお持ちの場合は、最新のドライバとCUDAツールキットをインストールしてください。
- モデルの更新:DeepSeek-R1モデルは継続的に更新される可能性があります。最新情報や詳細は、公式のドキュメントやコミュニティリソースを参照してください。
DeepSeek-R1のローカルLLM構築ガイド:まとめ

この記事では、Ollamaを活用してDeepSeek-R1をローカル環境で実行する手順を紹介しました。macOS、Linux、Windowsで動作可能なうえ、モデルサイズやGPUの有無に合わせて柔軟に構成できる点が特徴です。
さらに、日本語への追加学習モデルも充実しており、高精度な自然言語処理をプライベート環境で実現できます。オフライン利用によるデータ保護や、軽量なモデルを選んで個人PCでも動かせる利便性も大きな魅力です。今後はモデルやOllama本体の更新を追いかけながら、LM Studioなどとの使い分けも検討し、最適なローカルLLM構築を目指してみてください。
参考資料
Ollama公式サイト DeepSeekモデル cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese
lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese

