

昨今、大規模言語モデル(LLM)の活用が企業の競争力を左右する時代となっています。しかし、クラウドベースのAIサービスではデータプライバシーやコスト面での課題が残っていることでしょう。
本記事では、こうした課題を解決する方法として、日本語対応のオープンソースLLMをローカル環境で活用し、自社のニーズに合わせたカスタマイズを行う方法を解説します。具体的には、モデルのファインチューニング手法と、外部知識を活用するRAG(Retrieval-Augmented Generation)の構築手順を、実践的なステップに沿って説明していきます。

この記事の内容は上記のGPTマスター放送室でわかりやすく音声で解説しています。
基礎知識:RAGとファインチューニングの主な違いを理解する

まずはRAGとファインチューニングの違いをまとめたので、ご覧ください。
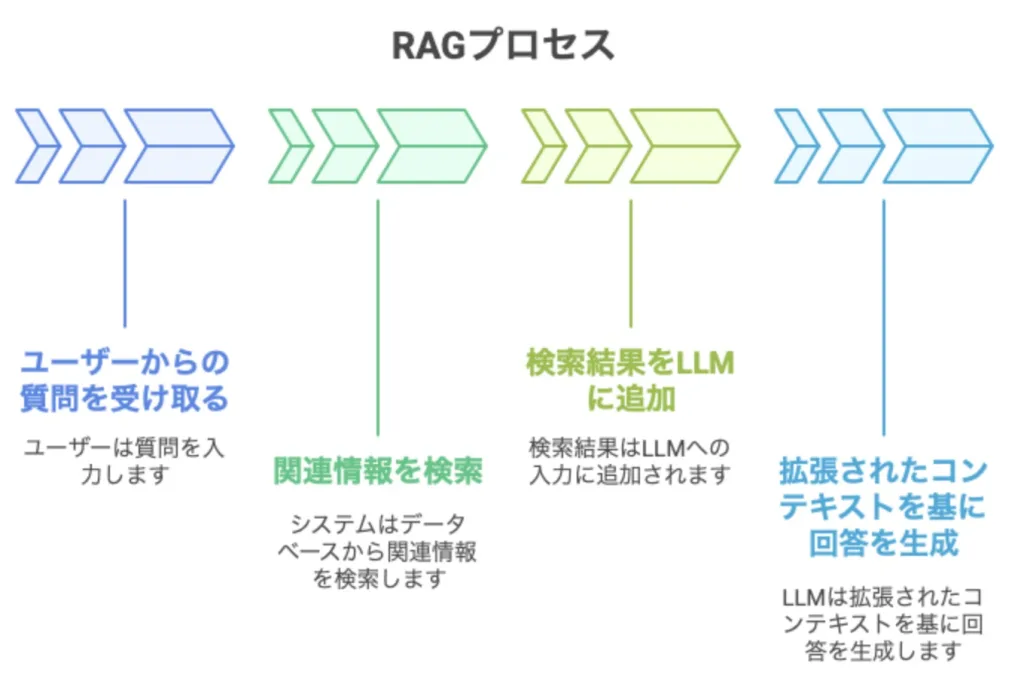
RAG(Retrieval-Augmented Generation)
RAGとは、AIの回答生成プロセスに「情報検索」の機能を組み込んだ手法です。従来のLLMが持つ知識の限界を超えるため、質問に応じて外部のデータベースから関連情報をリアルタイムで検索し、その情報を基に回答を生成します。
たとえば、「当社の新製品Xの特徴は?」という質問に対して、社内文書から製品Xに関する情報を検索し、それを踏まえた回答を生成できます。重要なポイントは、モデル自体は変更せず、外部知識を「コンテキスト」として活用する点です。
ファインチューニング
既存のモデルに新しいデータを追加して再学習させ、特定のタスクや用途に適したモデルに調整する手法です。モデル自体を更新します。
一般的に、RAGは初期設定や運用が比較的手軽であり、特に最新情報の取得や頻繁なデータ更新が求められる場合に適しています。一方、ファインチューニングは初期のデータ準備や学習に手間がかかるものの、特定のタスクにおいて高い精度が求められる場合に有効です。
ローカルLLMのファインチューニングとRAG構築のメリット

顧客対応や文書作成に役立つ!
ローカルLLMをファインチューニングすることで、特定の業務ニーズに応じたカスタマイズを可能にします。特定の業務ニーズとは、たとえば顧客対応や文書作成、翻訳などです。
日本語特有のニュアンスや業界特有の用語やデータを理解したモデルを構築することで、さまざまなビジネスシーンで質の高いサービス提供を実現します。
RAGを構築することで知識不足を補完できる
RAGの構築によって、過去の顧客とのやり取りや会話履歴など、外部知識を活用しながら生成AIの性能を向上させることができます。外部知識の活用によって特定のドメインや話題に関する知識不足を補完できるため、業務効率が大幅に向上します。
ローカルLLMを利用するメリット
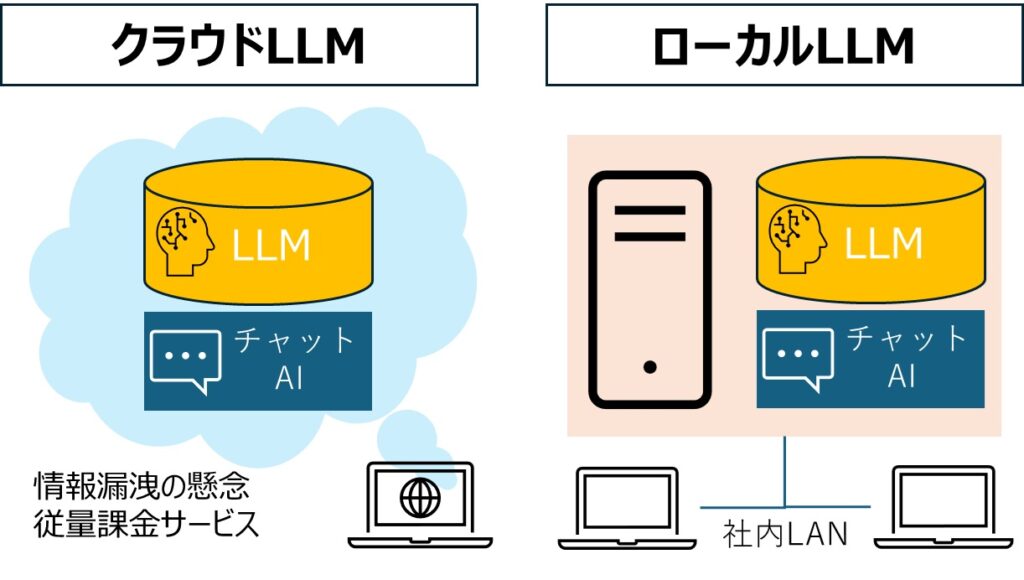
1.データプライバシーとセキュリティの向上
ローカル環境でLLMを運用することで、機密データが外部サーバーに送信されることがなくなります。その結果、情報漏洩のリスクを大幅に低減し、とくに個人情報や企業秘密を扱う業務において安心して利用できます。
2.業務特化型のカスタマイズ性
自社固有の業務内容やデータに特化した形でモデルをファインチューニングできることが、ローカルLLMの大きな強みです。
たとえば、社内で使用される専門用語や業界特有の表現を学習させることで、一般的なAIサービスでは対応できない高精度な業務支援が可能になります。これにより、文書作成や情報検索などの業務効率が飛躍的に向上します。
3.オフライン環境での利用
インターネット接続が不要なため、安定した通信が確保できない状況下でもLLMを活用できます。たとえば、ネット環境のない工場や建設現場などでも利用可能です。
4.コスト削減
クラウドサービス利用料やAPIコール費用などのランニングコストを抑えることが可能です。とくにLLMを大規模に活用する場合、そのコストメリットは大きくなります。
ローカルLLMのユースケース

製造業
製品開発におけるアイデア創出やマニュアル作成の自動化などで活用できます。過去の製品情報や技術文書を学習させれば、より自社に合った新製品のアイデア創出や設計開発になるでしょう。
医療分野
電子カルテの自動作成や医療画像診断の支援などで利用されます。医師の音声データをリアルタイムでテキスト化し、電子カルテへの入力を自動化することで、医師の事務作業負担を軽減します。
教育分野
個別最適化された学習体験の提供や教材作成の自動化などで活用されます。生徒一人ひとりの学習進度や理解度に合わせて、最適な教材や問題を提供するアダプティブラーニングが実現可能です。
金融分野
不正取引の検知や顧客対応の自動化などで利用されます。過去の取引データから不正取引パターンを学習し、リアルタイムで不正検知が行えます。
法人向けのローカルLLMサービス
LM StudioやOllamaなどを使えば、個人のPCでローカルLLMを動かすことは可能です。ただし、自社データを活用したローカルLLMを構築したい場合は、RAGの機能が不足しています。
法人向けにおすすめのローカルLLMサービスにご興味がある方は以下をご覧ください。

ローカルLLMのファインチューニングする手順

ステップ1: 環境の準備
まず、Pythonや必要なライブラリ(例: transformers, langchain, chromadbなど)をインストールします。Google Colaboratoryやローカル環境での実行が可能です。
また、Hugging Faceに登録し、モデルへのアクセス権を取得します。Llama系モデルはGated Modelとして提供されているため、利用権限の申請が必要です。
ステップ2: モデルの選定とファインチューニング
続いてモデル選定とファインチューニングを行います。
モデルの選定
日本語対応のオープンソースLLMから適切なモデルを選びます。たとえば、Meta社のLlamaやGoogle社のGemmaなどが候補です。
ファインチューニング
選定したモデルを特定のタスクに合わせてファインチューニングします。LoRA(Low-Rank Adaptation)などの手法を用いることが一般的です。

以下のPythonコードを使用してファインチューニングを実行します。このコードでは、Meta社のLlama 3(8Bパラメータ版)をベースモデルとして使用し、LoRA手法によって効率的なファインチューニングを行っています。
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, PeftModel
from trl import SFTTrainer
model_name = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# LoRA設定
lora_config = LoraConfig(r=64, lora_alpha=16, lora_dropout=0.1)
trainer = SFTTrainer(model=model, tokenizer=tokenizer, peft_config=lora_config)
trainer.train()
ステップ3:RAG構築
RAGは情報検索と生成を組み合わせた手法です。以下の手順でRAGを構築します。
データベースの準備
RAGでは外部データベースから情報を取得するために、ChromaDBなどのベクトルストアを使用します。データベースには関連する文書や情報を格納しておきます。
情報検索機能の実装
LangChainなどを用いて、ユーザーからの質問に対して関連する情報をデータベースから検索する機能を実装します。
生成モデルとの統合
検索した情報を基に生成モデルが回答を生成するように設定します。以下はその一例です。
from langchain.chains import RetrievalQA
from langchain.vectorstores import Chroma
# ベクトルストアから情報取得
vectorstore = Chroma.from_documents(texts, embeddings)
qa_chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 質問応答
response = qa_chain.run("データアナリティクスラボ株式会社について教えてください。")
ステップ4: テストと評価
構築したRAGシステムが正しく動作するかどうかテストします。様々な質問に対して期待通りの回答が得られるか確認し、必要に応じてモデルやデータベースの調整を行います。
ローカルLLMをファインチューニングしてRAG構築:まとめ

日本語対応のオープンソースLLMを活用したローカルLLMのファインチューニングとRAG構築は、高度な自然言語処理能力を持つシステムを自分自身で構築するための強力な手段です。
このプロセスでは、環境設定から始まり、モデル選定、ファインチューニング、RAG構築まで一連の流れがあります。ローカルLLMをファインチューニング、そしてRAG構築することで、自分自身やビジネスニーズに合わせたカスタマイズ可能なAIシステムが実現できます。

